
はじめに
ChatGPTのような大規模言語モデル(LLM)をローカルで動かす場合、先日、OllamaとOpenWebUIを使用するやり方を解説しましたが、今回は、LM Studioを使用したやり方を解説したいと思います。一つのアプリで完結しているため、ローカルLLMを使うだけならこちらのほうが簡単です。
前回の記事については、こちらをご参照ください。

LLMをローカルで動かすメリット
LLMをローカルで動かした場合、
- データが外部に漏れない
- 回数制限がなく、いくらでも使用可能
- オフラインで使用できる
以上の3点がメリットとしてあげられます。
制限を気にせず、気軽に使えるところがとてもいいですね。
LM Studioの強み
LMStudoでは、モデルの検索とダウンロードが簡単にできます。Hugging faceからモデルを検索でき、一つのモデルに対して、数種類の量子化(データの軽量化)されたモデルを簡単にダウンロードすることができます。
LMStudioのインストール
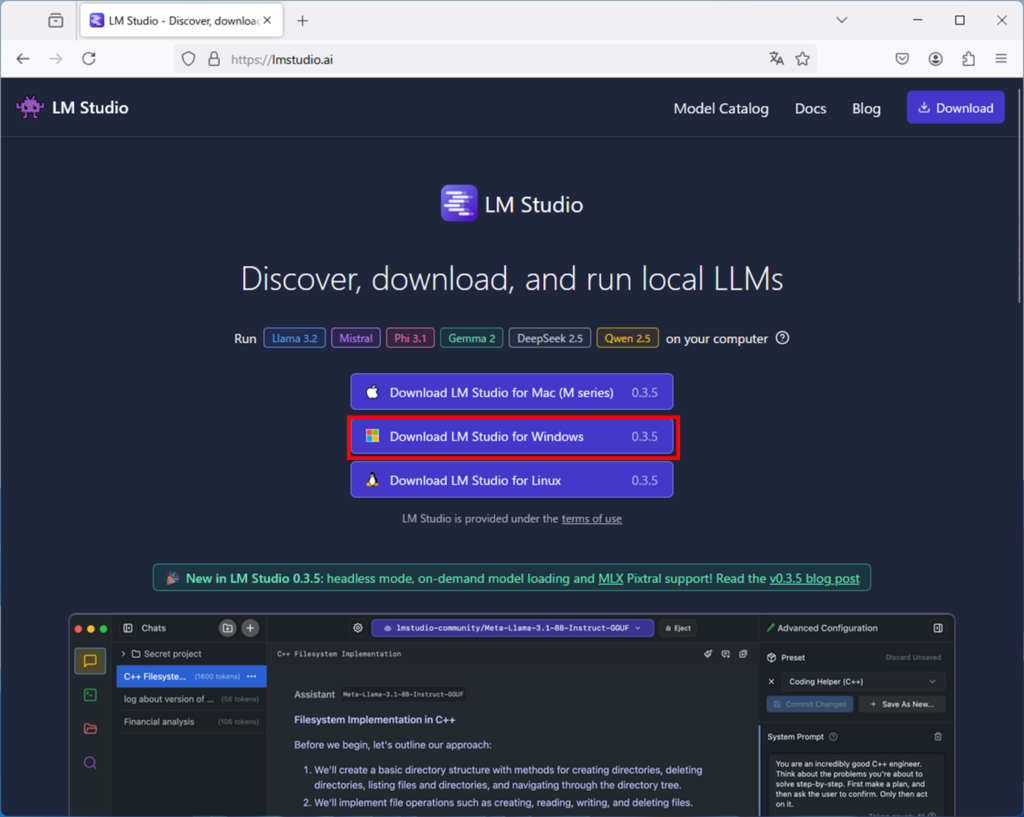
LMStudioを公式サイトからダウンロードします。

Download LM Studio for Windowsを選択してダウンロードします。
ダウンロードしたファイルをダブルクリックしてインストールします。
インストールが終わったら、LMStudioを起動します。
デスクトップにアイコンができていますので、ダブルクリックで起動します。
起動したら、最初のモデルをダウンロードしましょうの画面がでます。
右上のSkip onboardingをクリックしてスキップしましょう。
言語が英語設定なので、日本語に変更します。
右下の歯車のアイコンを押しましょう。
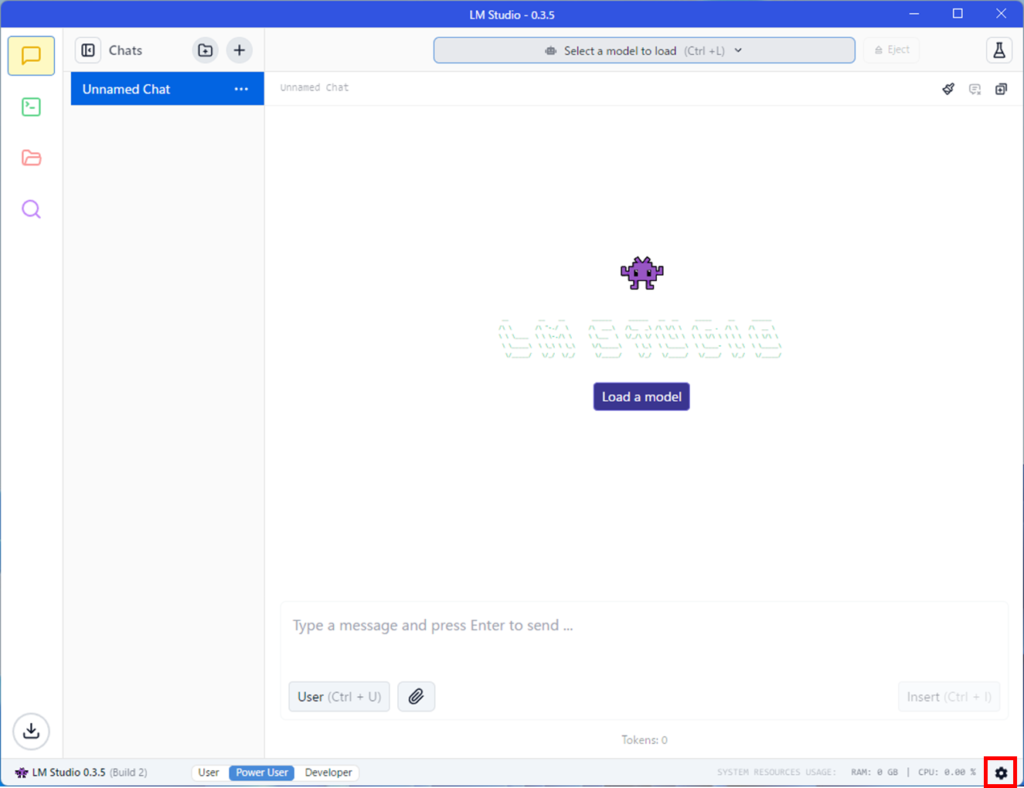
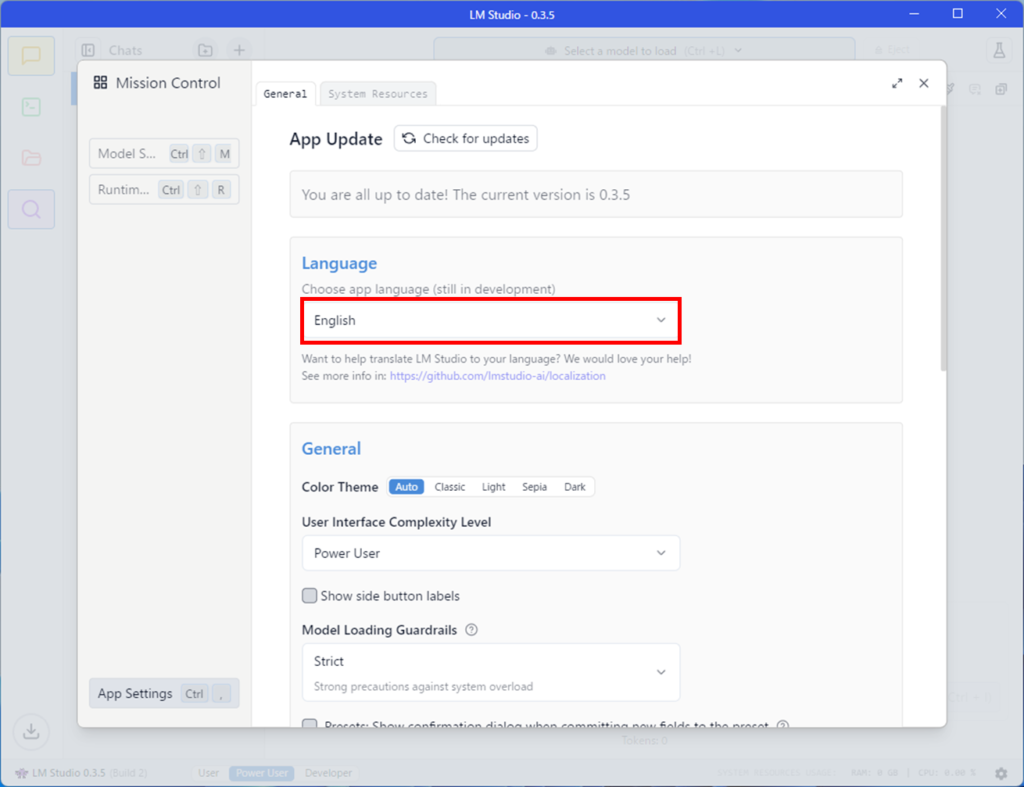
LanguageのところをEnglishから日本語に変更します。
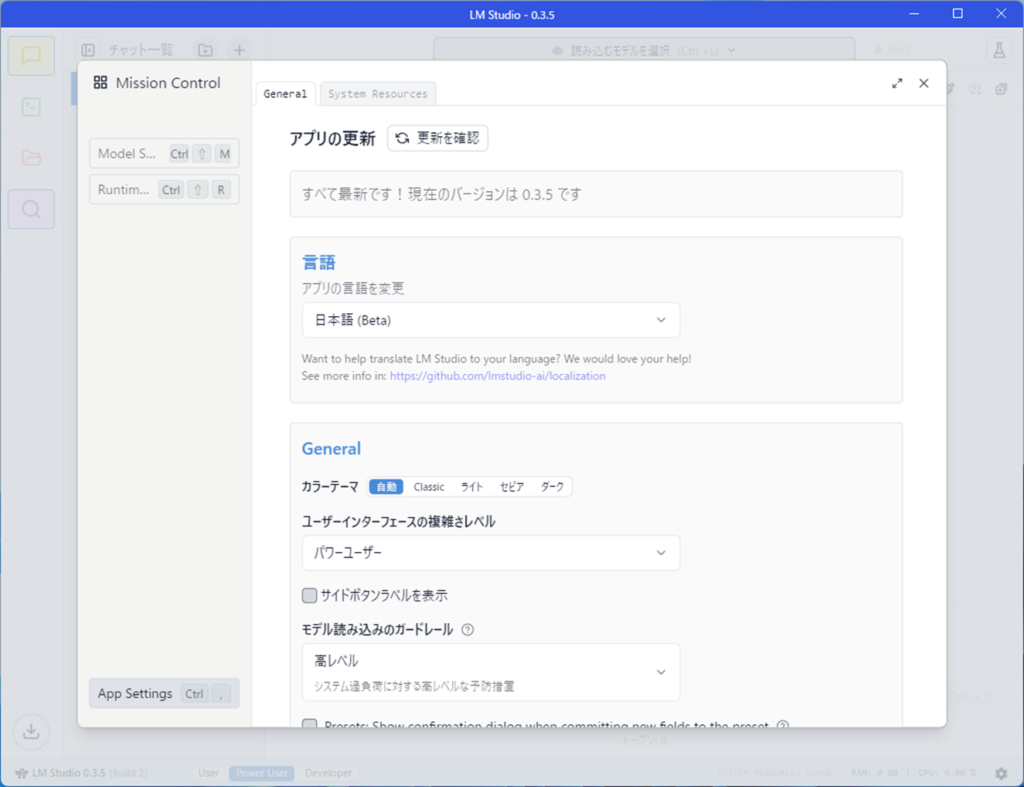
日本語設定になり、アプリが日本語表示になりました。
次にモデルをダウンロードします。左上の虫眼鏡のアイコンを押します。
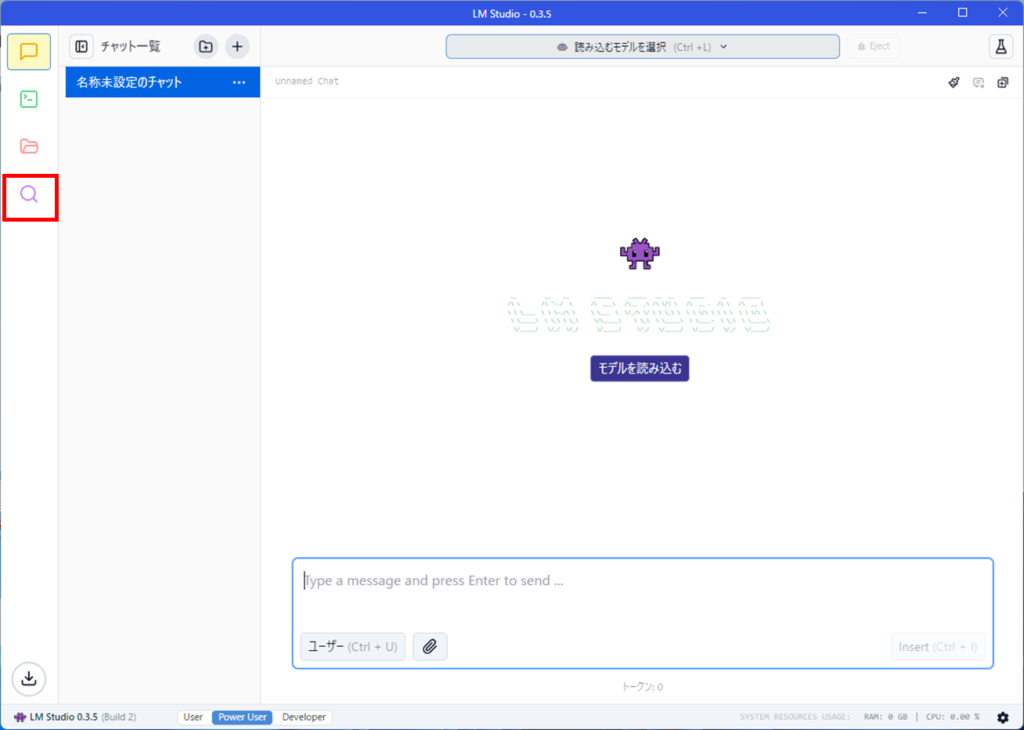
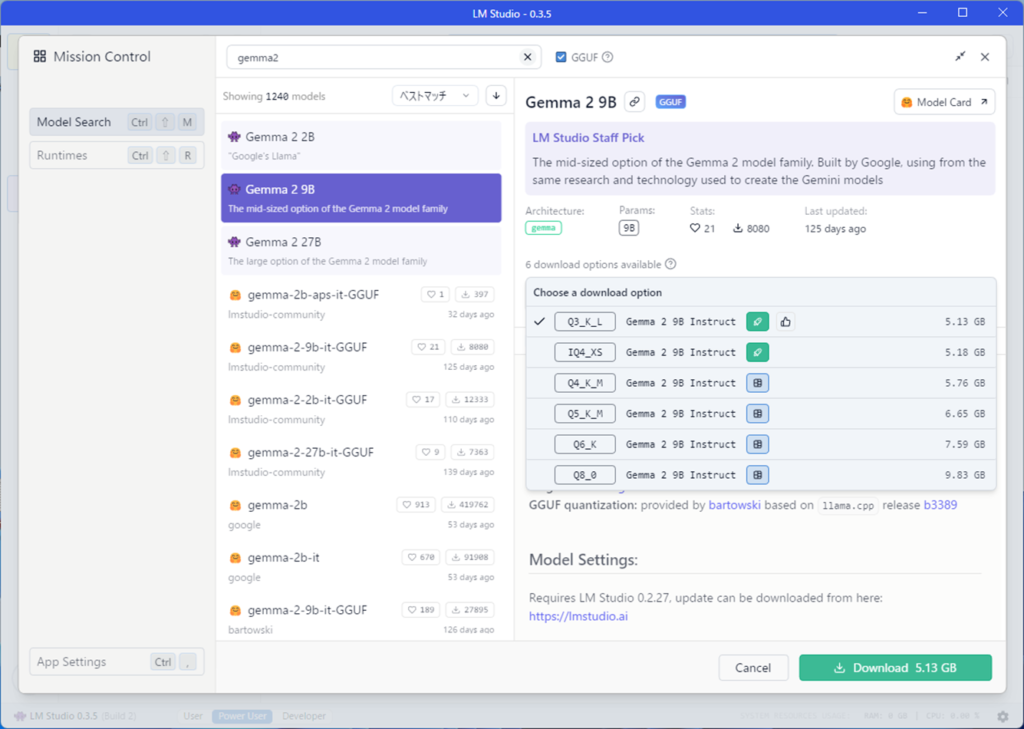
Hugging Faceでモデルを検索と書いてあるテキストボックスにgemma2と入力します。
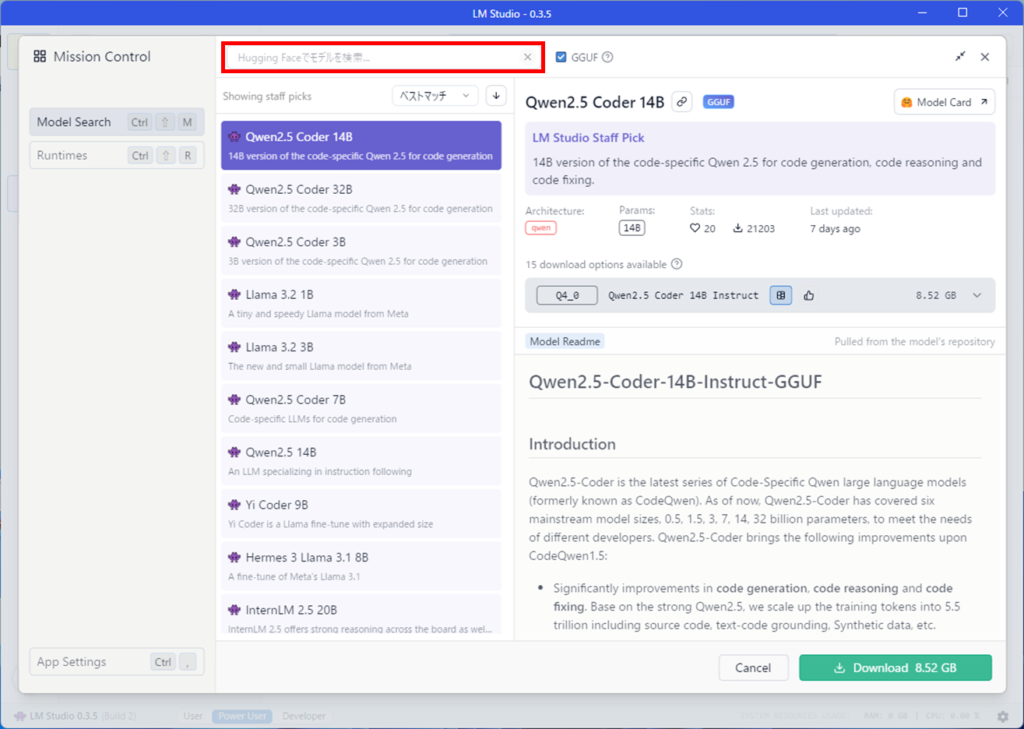
Gemma2 9Bを選択し、灰色になっているところを選択します。
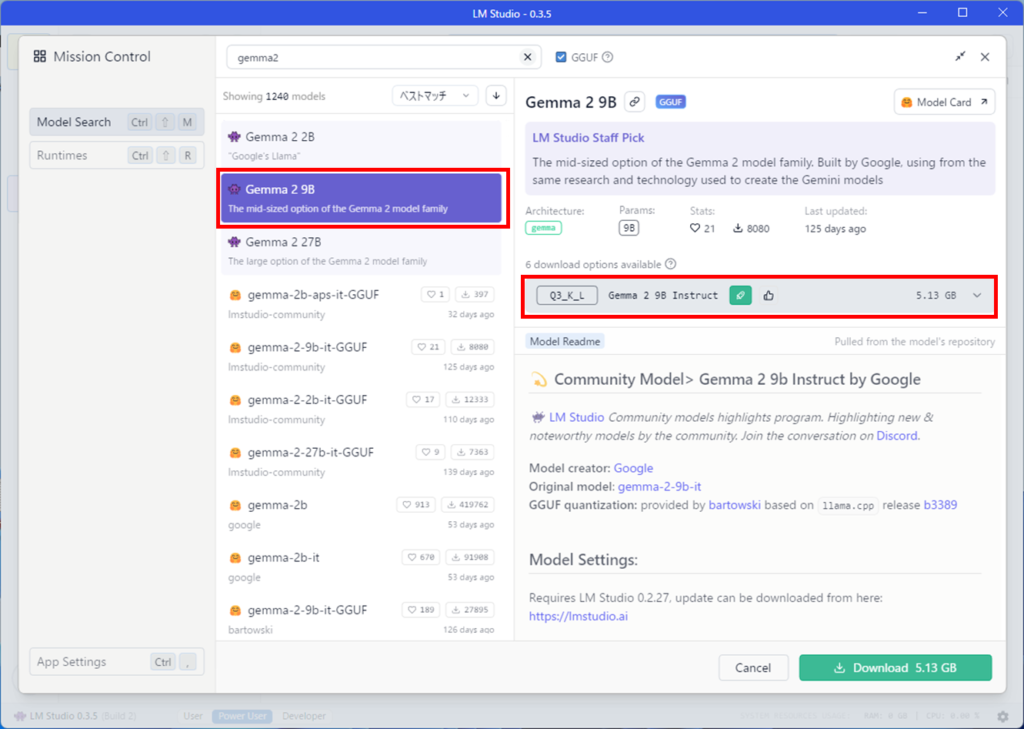
6つのオプションがあることが分かります。
Q3_K_Lをダウンロードしてみましょう。Q3_K_Lが選択されていることを確認して、Downloadボタンを押します。
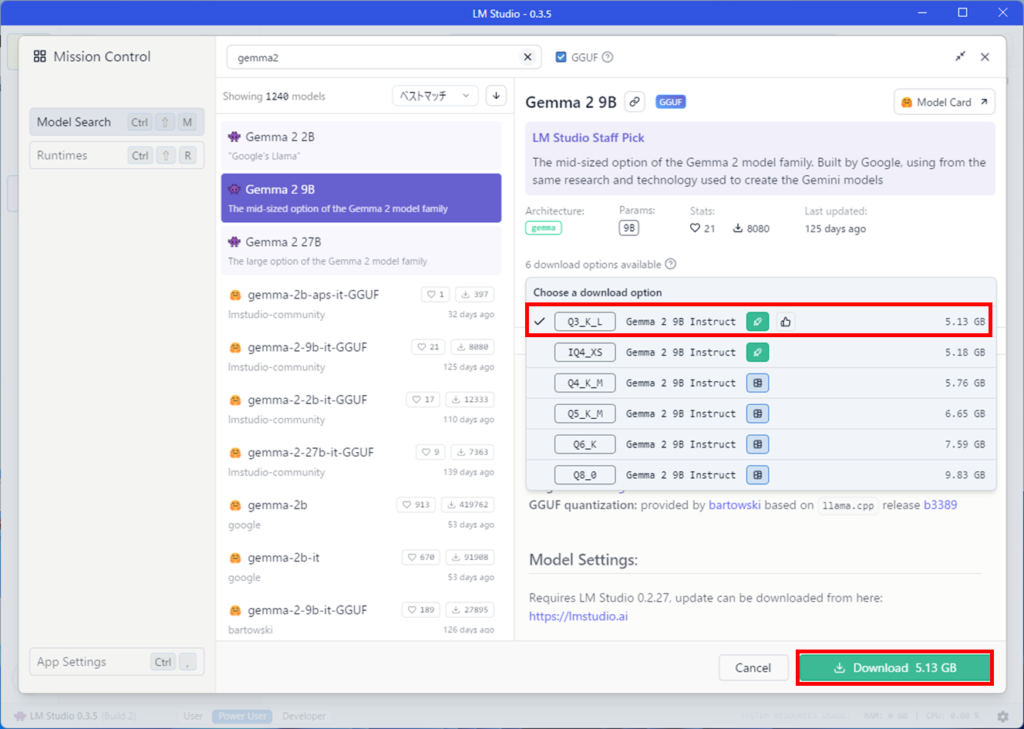
補足
Q3_K_Lなどの文字列は、量子化(いわゆる軽量化)されていることを示していて、LLMのモデルサイズを小さくして、容量を少なく、早く計算できるようにしたものになります。
ダウンロードが始まるとダウンロードウィンドウが開きますので、終わるまで待ちます。
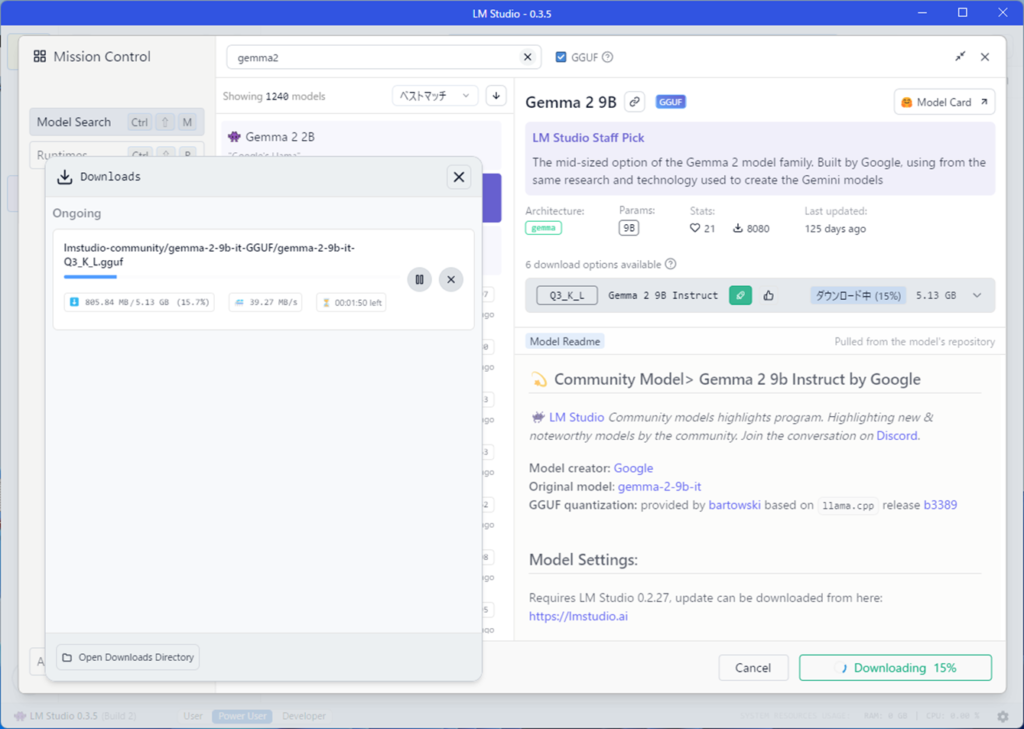
ダウンロードが終わったら、左上の吹き出しアイコンを押します。
その後、読み込むモデルを選択のボタンを押しましょう。
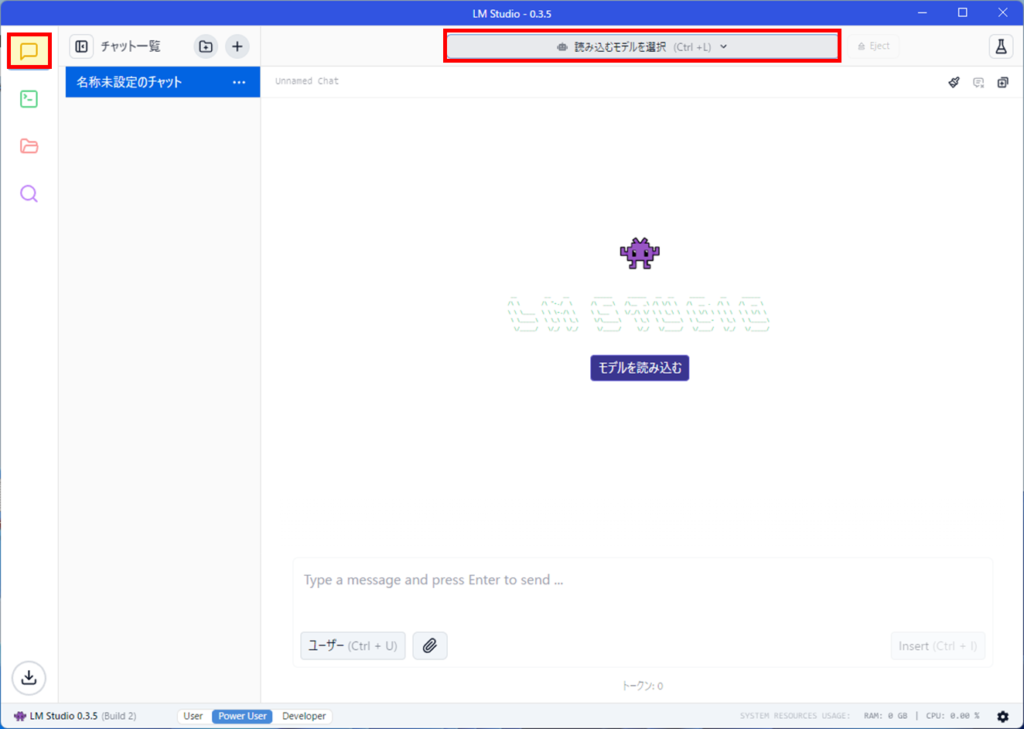
先ほどダウンロードした、Gemma2 9Bが表示されますので、選択します。
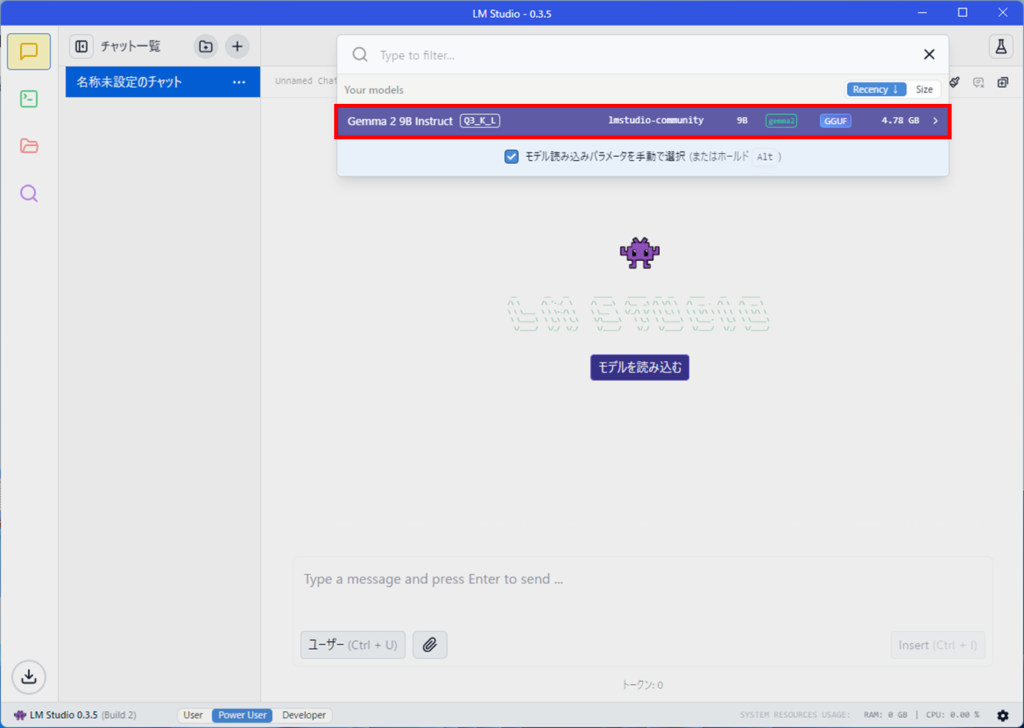
モデルをロードする際の設定値が表示されます。
特に変更せずデフォルト値でOKです。モデルを読み込むボタンを押します。
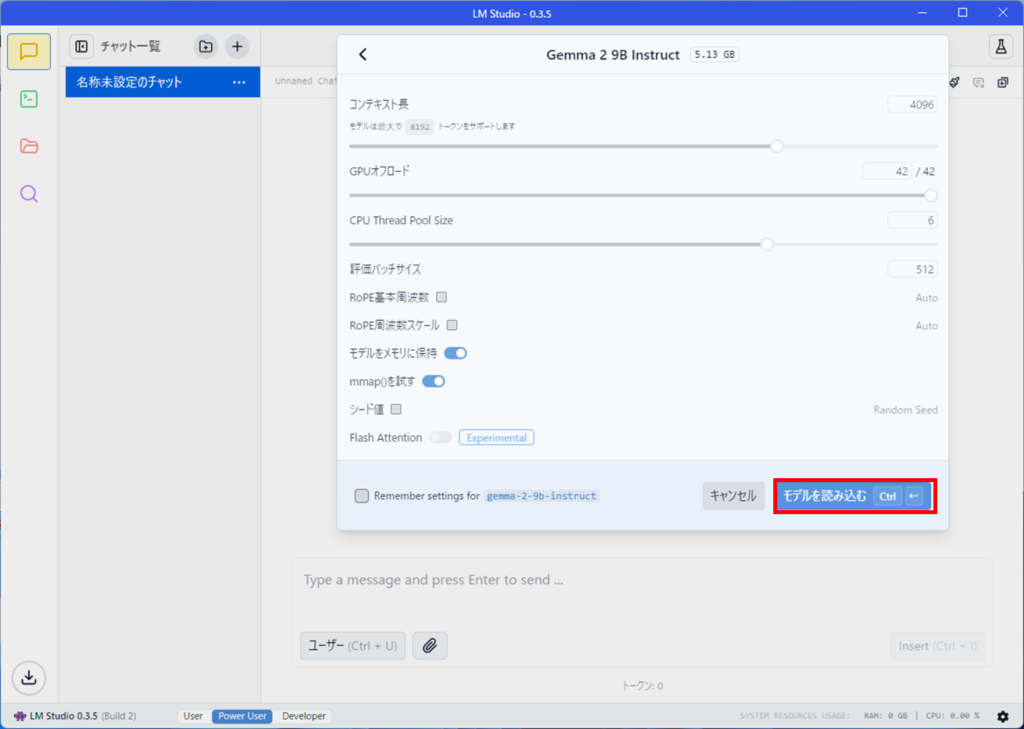
読み込みが完了したら、チャット欄でコーヒーのおいしい入れ方について聞いてみます。
コーヒーの入れ方についての回答が表示されました。
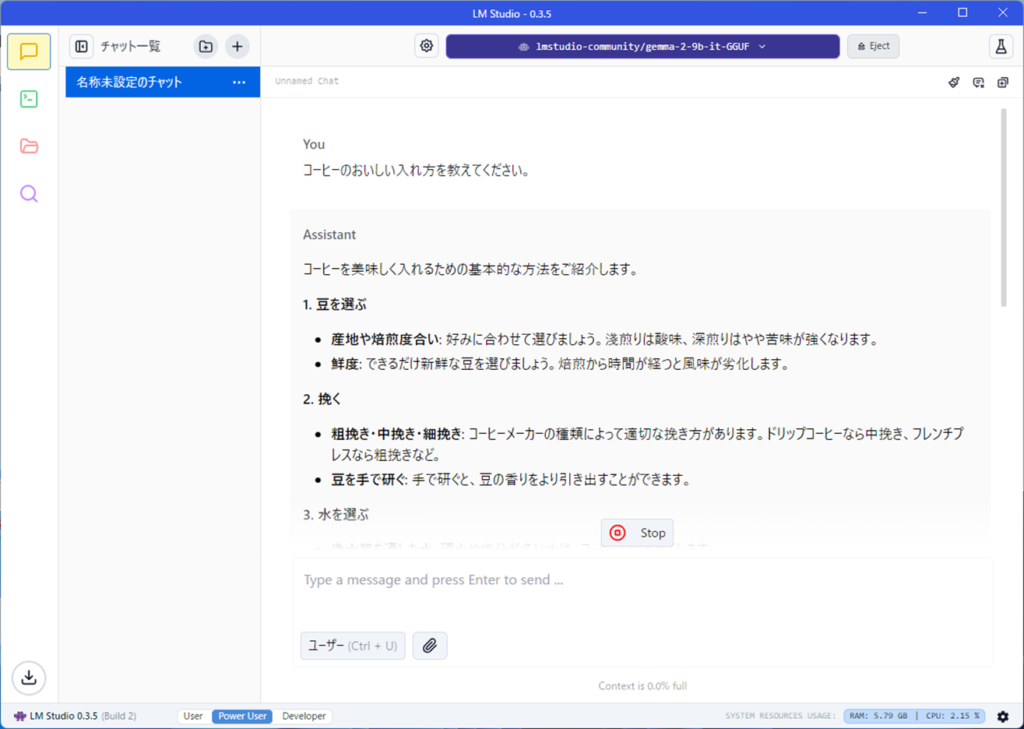
以上で、ローカルでLLMを使うことができます。とても簡単ですね。
サーバーの立て方
LM Studio側の設定
LM Studioはサーバーとして使用することもできます。
自宅のパソコンを1台サーバーとしてローカルLLMをインストールしておき、ほかのパソコンからローカルLLMを使うという使い方ができます。LM Studioにサーバーの機能があるため、難しくありません。まず開発者のアイコンを押します。
読み込むモデルを選択を押します。
ダウンロードしたモデルを選択しましょう。ここでは、Gemma2 9Bを選択しています。
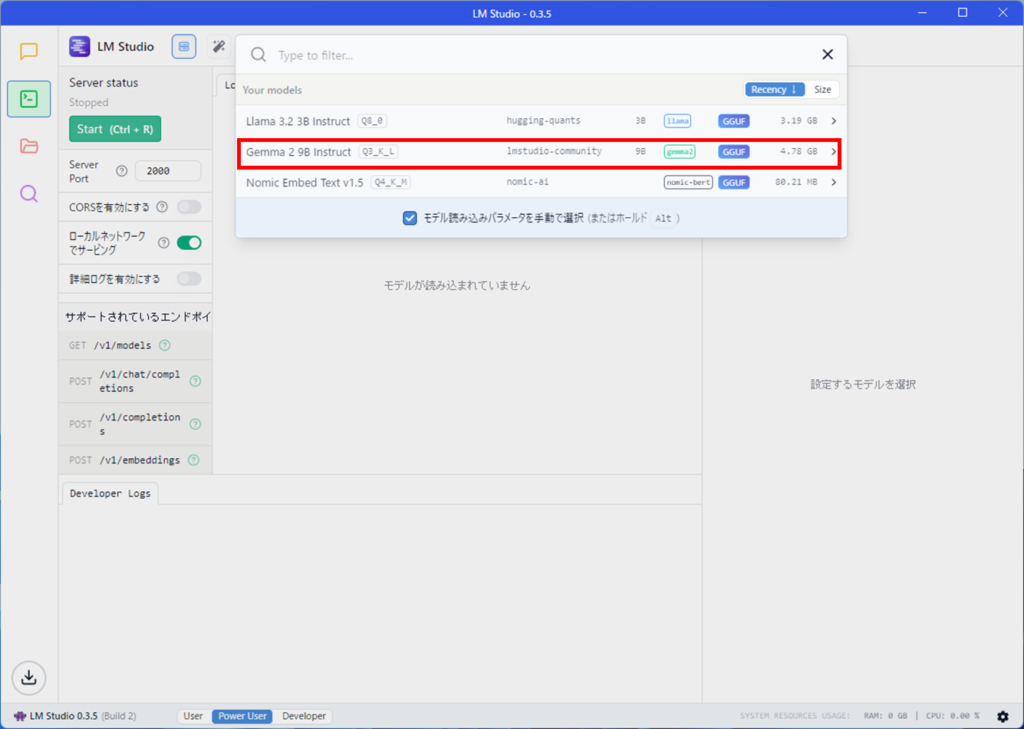
モデルをロードする際の設定値が表示されます。モデルを読み込むボタンを押しましょう。
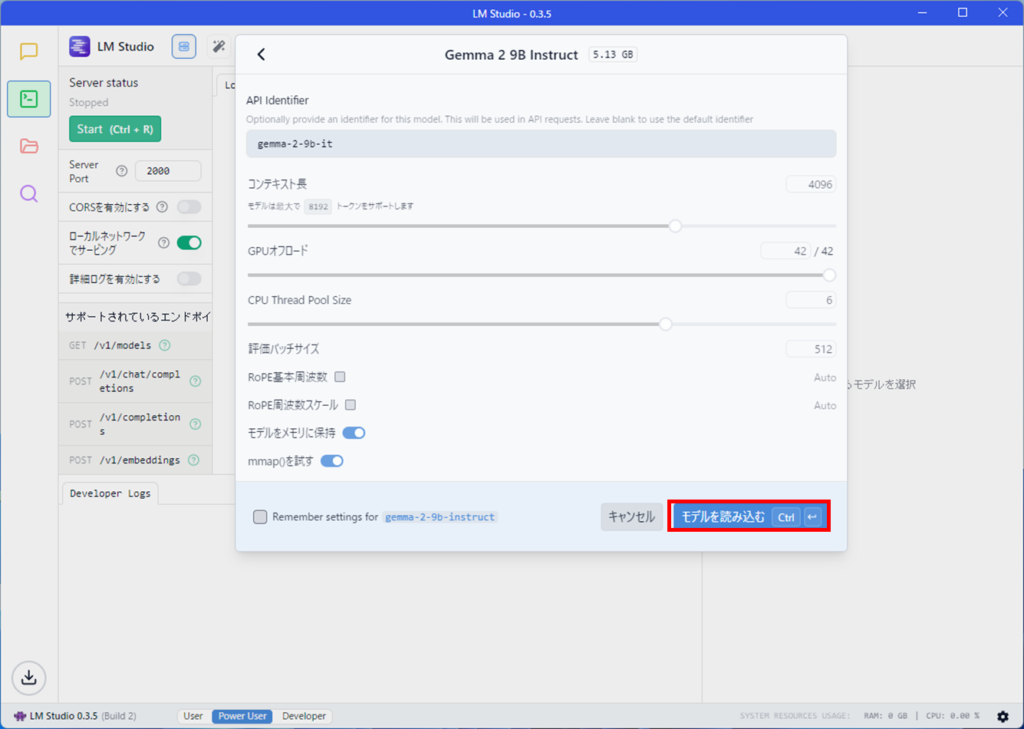
サーバー運用の場合は、複数のモデルを読み込むことができます。
ここでは、llama3.2を追加で読み込んでみます。
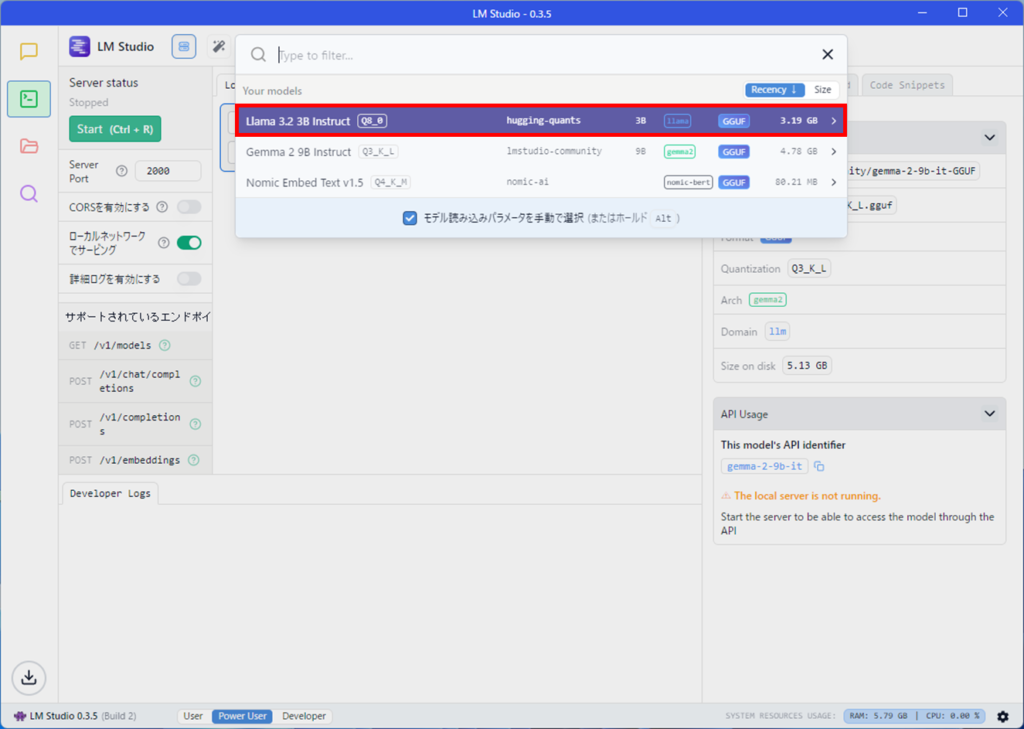
モデルを読み込むボタンを押します。
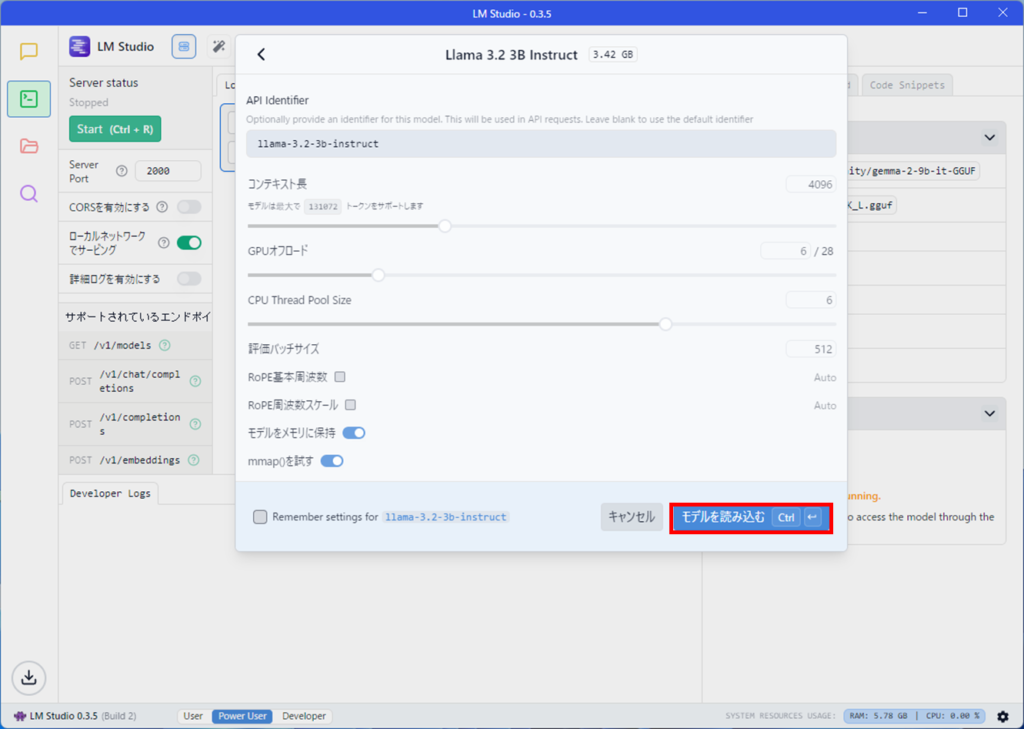
モデルをロードし終わると、Load Modelsのところに2つのモデルがセットされています。
Server satusの下にある緑色のStartボタンを押しましょう。
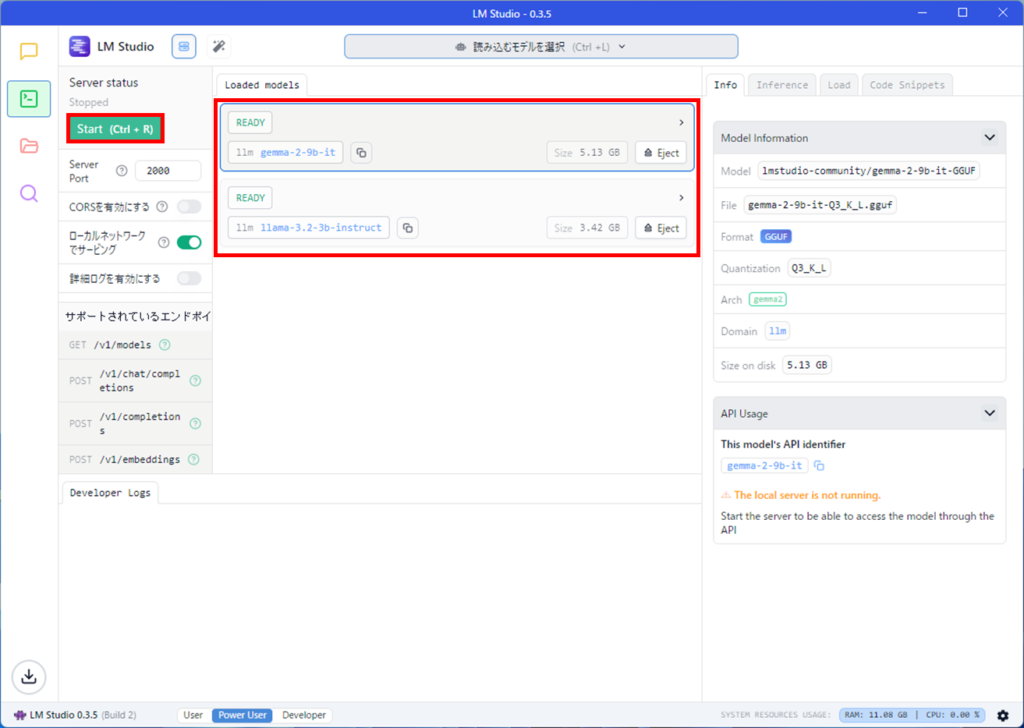
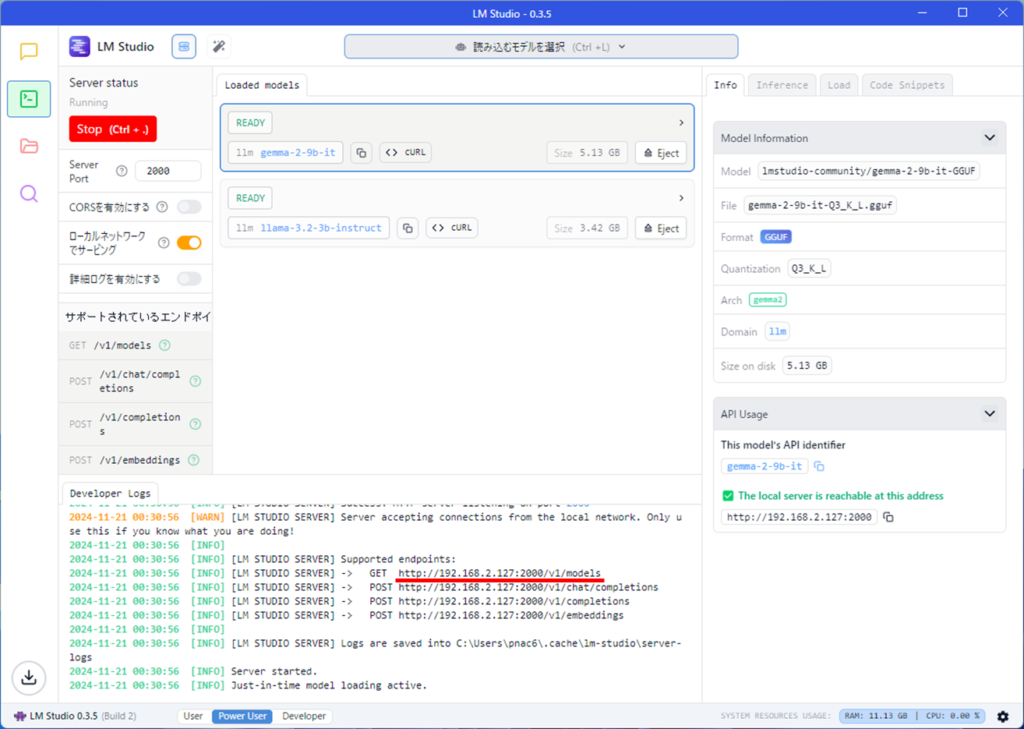
サーバーが開始され、緑色のボタンが赤くなります。
赤線の部分がサーバーのアドレスになります。(後で使用しますので、ひかえておきましょう)
DockerDesktopのインストール
DockerDesktopをダウンロードします。

ダウンロードしたインストールファイルを実行します。
OKボタンを押します。
インストールが完了すると、Close and restartボタンを押すとパソコンが再起動します。
再起動後、以下のような画面が出るので、Acceptを押します。
Dockerアカウントを持っていない方は、アカウントを作成しましょう。
Create an accountボタンを押します。
OpenWebUIのインストール
スタートメニューを右クリックして、ターミナル(管理者)を選択します。
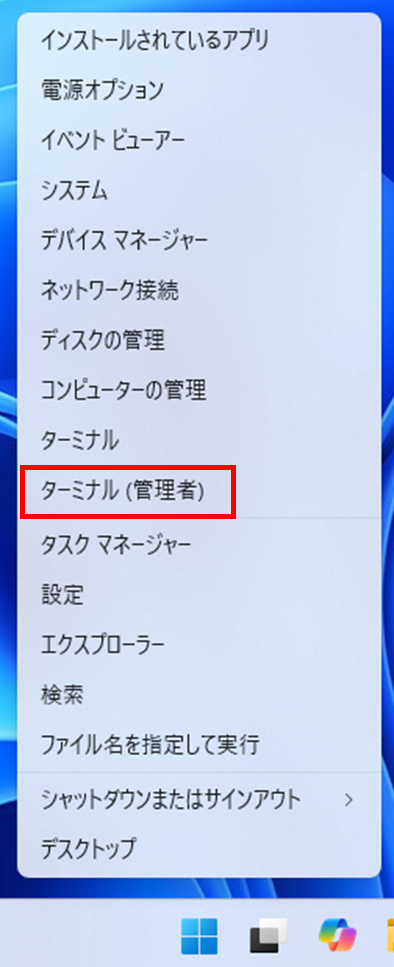
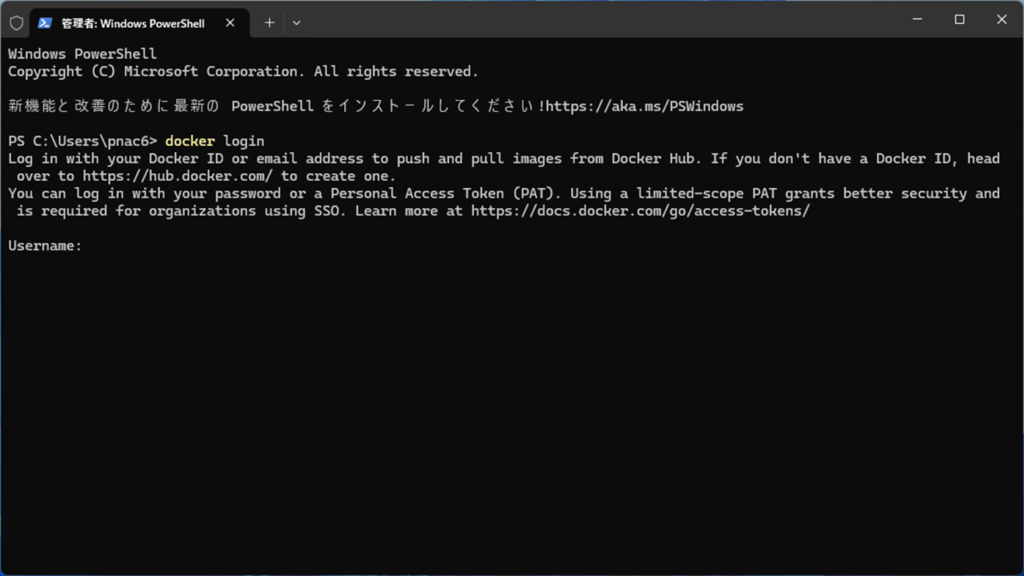
以下のコマンドを入力します。
docker loginユーザー名とパスワードを入力します。
次に以下のコマンドを入力します。
git clone https://github.com/open-webui/open-webui.gitcd open-webuidocker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainインストールが成功すると、DockerのコンテナにOpen-WebUIが追加されます。
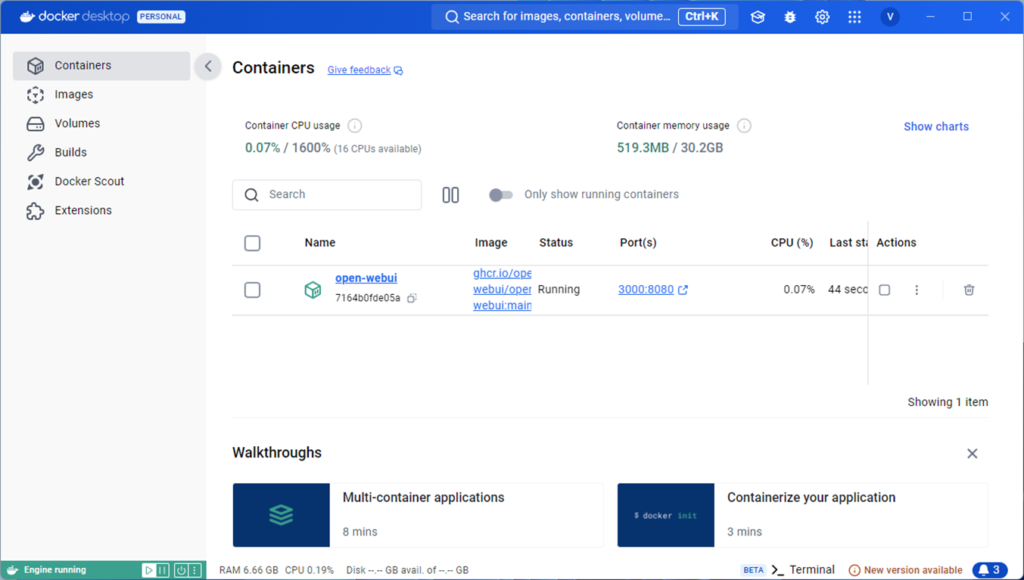
OpenWebUIにアクセスする
インストールしたDockerDesktopを起動します。
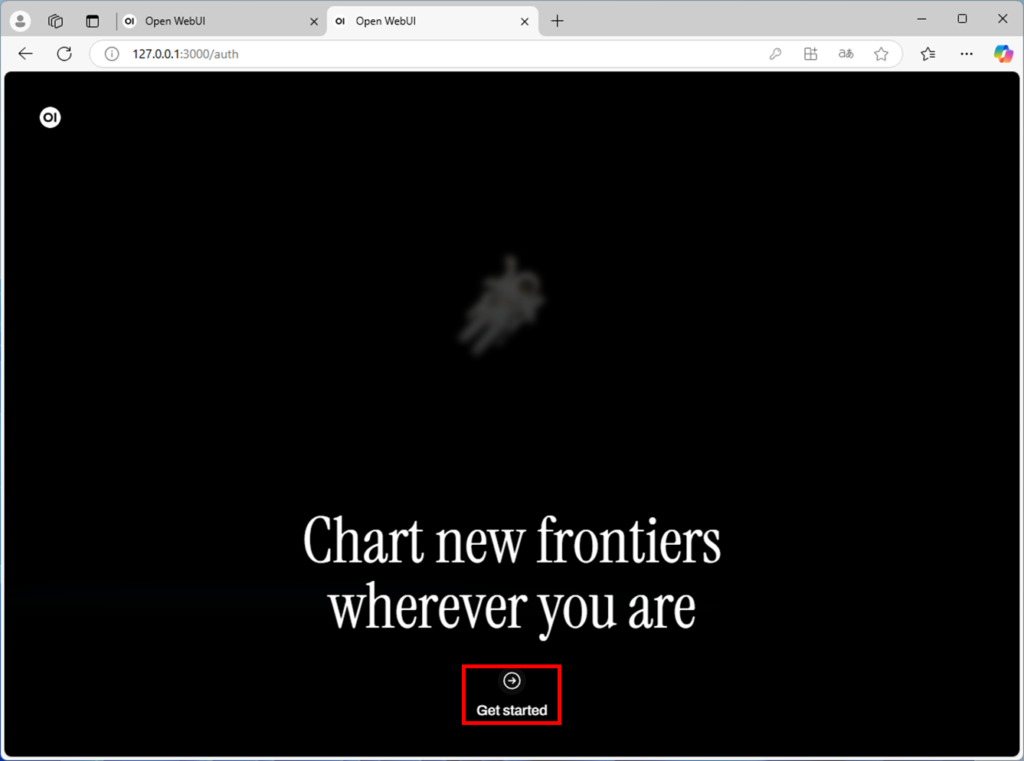
ブラウザーからhttp://127.0.0.1:3000と入力します。
下記のような画像が出た場合は、GetStartedを押します。
初回起動時にはアカウント作成が必要です。サインアップを押しましょう。
名前、メールアドレス、パスワードを入力してアカウントを作成ボタンを押します。
アカウントを作成でき、ログインできたら、右上のアイコンを押して、設定を選択します。
管理者設定を押します。
接続を押すと、OpenAI APIという項目があります。
ここの文字列を、「サーバーの立て方」の「LM Studio側の設定」の最後で控えておいた文字列に変更します。下の絵のさらにひとつ下に絵を貼り付けておきます。文字列の場所を確認してください。
ここでは、左側にhttp://192.168.2.127:2000/v1 右側にnoneと入力しています。
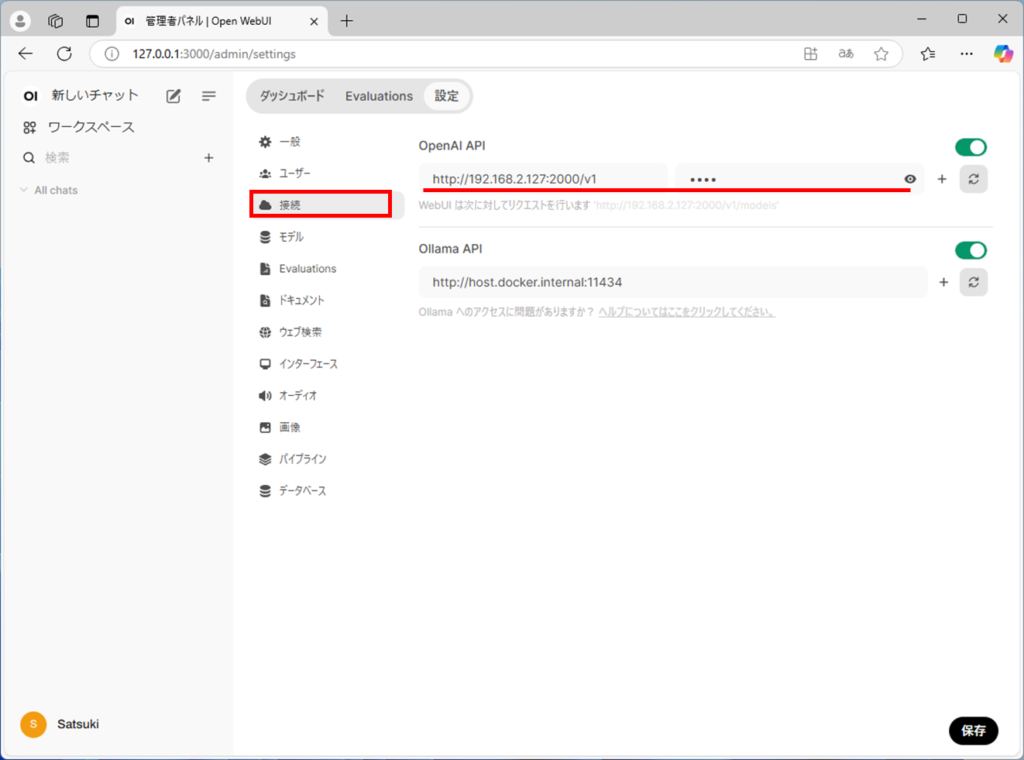
文字列はこの場所にあります。v1までの文字列を参照してください。
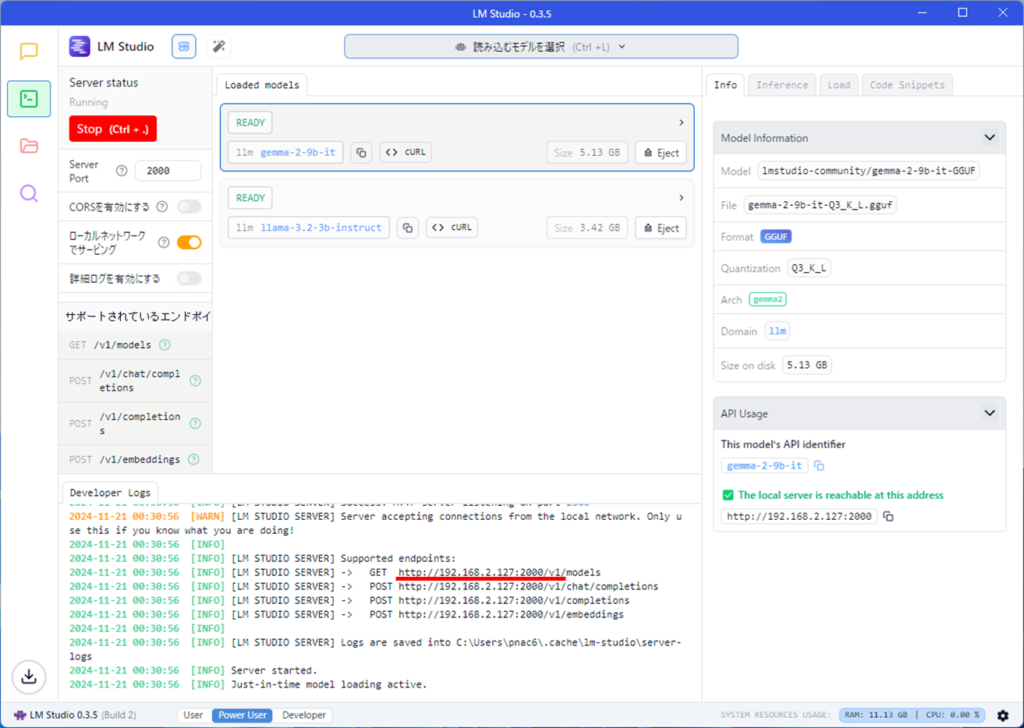
リサイクルマークみたいなボタンを押します。
接続が成功したら、サーバー接続が確認されましたのポップアップが表示されます。
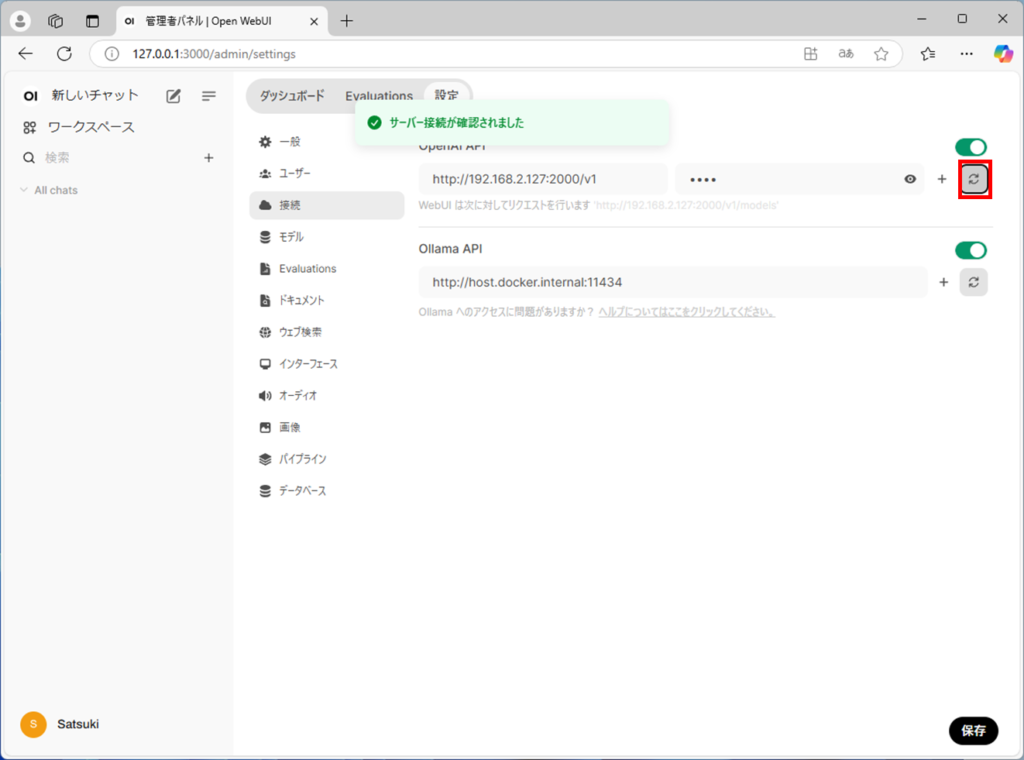
以上で設定は終わりです。
チャットの左上で、モデルを選択します。今回はgemma2を選択してみます。
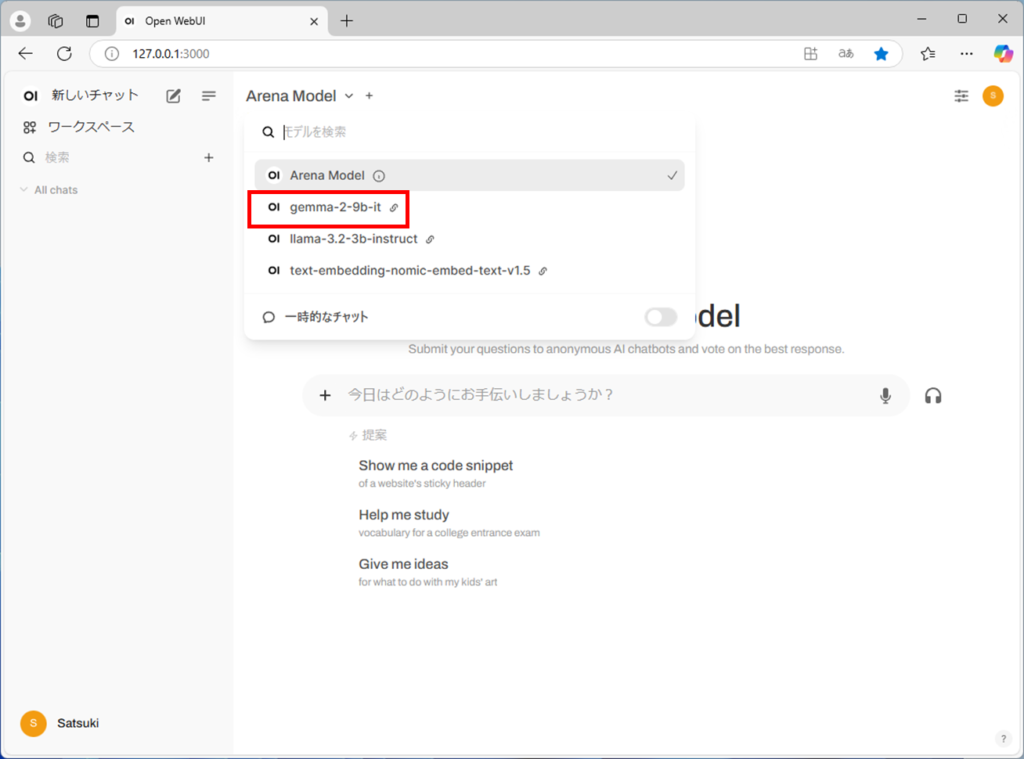
チャットで質問すると、回答が表示されます。
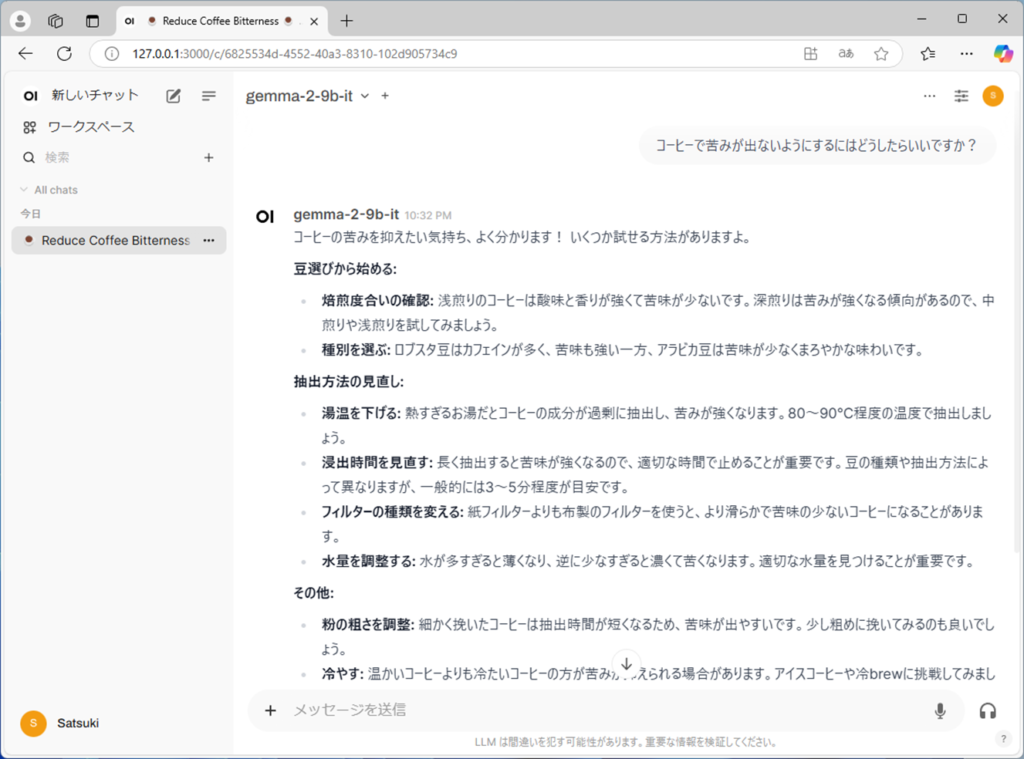
サーバーを立てることで、処理の早いデスクトップパソコンなどにローカルLLMを入れておき、ノートパソコンなどからローカルLLMを使うことができます。
まとめ
ローカルLLMを使う場合、LM Studioを使うのが一番簡単なやり方になります。
外部のサービスを使うこともできますが、ローカルLLMのほうが制限を気にせずに気兼ねなく使うことができます。今回、LM Studioというアプリの使い方を解説しましたが、使い方も簡単で、オープンソースで無料で利用することができます。LM Studioなどのアプリもそうですが、LLMモデルもどんどん進歩していっているので、今後のアップデートがとても楽しみですね。


コメント