
はじめに
ChatGPTのような大規模言語モデル(LLM)が最近流行っていますが、これらをローカルで動かすことができます。この記事では、LLMをローカルで動かすメリットと、必要な手順について解説します。
LLMをローカルで動かすメリット
プライバシー保護
データをネット上に送信する必要がなく、機密情報や個人情報の漏洩の心配がありません。無料サービスの多くは、送信した情報を学習に使うため、機密情報や個人情報については入力しないようにしたほうがよいです。
オフラインで使える
インターネット接続がなくてもLLMを利用できます。
カスタマイズ性
モデルの微調整や、独自のデータセットでの追加学習などが可能になります。
いくらでも使える
回数制限などを気にせずに使いたいだけ使うことができます。
LLMをローカルで動かすために必要な環境
グラフィックボード(VRAM8GB以上推奨ですが、なくてもCPUだけで動作できます)
Docker Desktopのインストール
Ollamaのインストール
OpenWebUIのインストール
LLMをローカルで動かす手順
Docker Desktopをインストール
DockerDesktopをWebからダウンロードします。

Docker Desktop Installerを起動します。
インストーラーが起動したら、OKを押します。
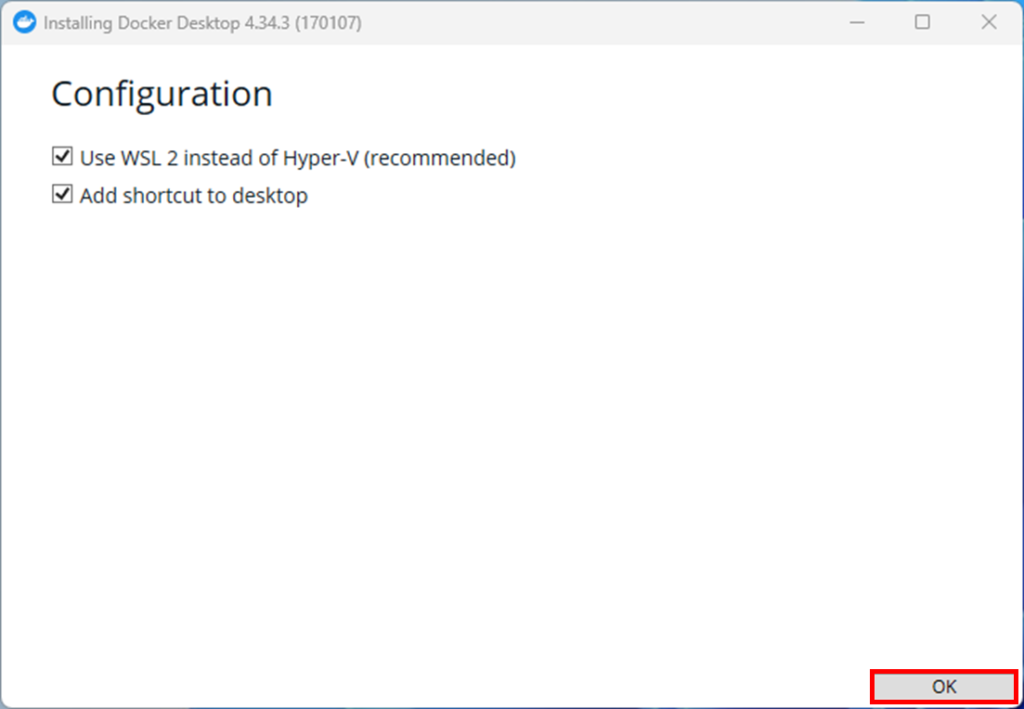
インストールが完了すると、再起動が必要になります。Close and restartを押します。
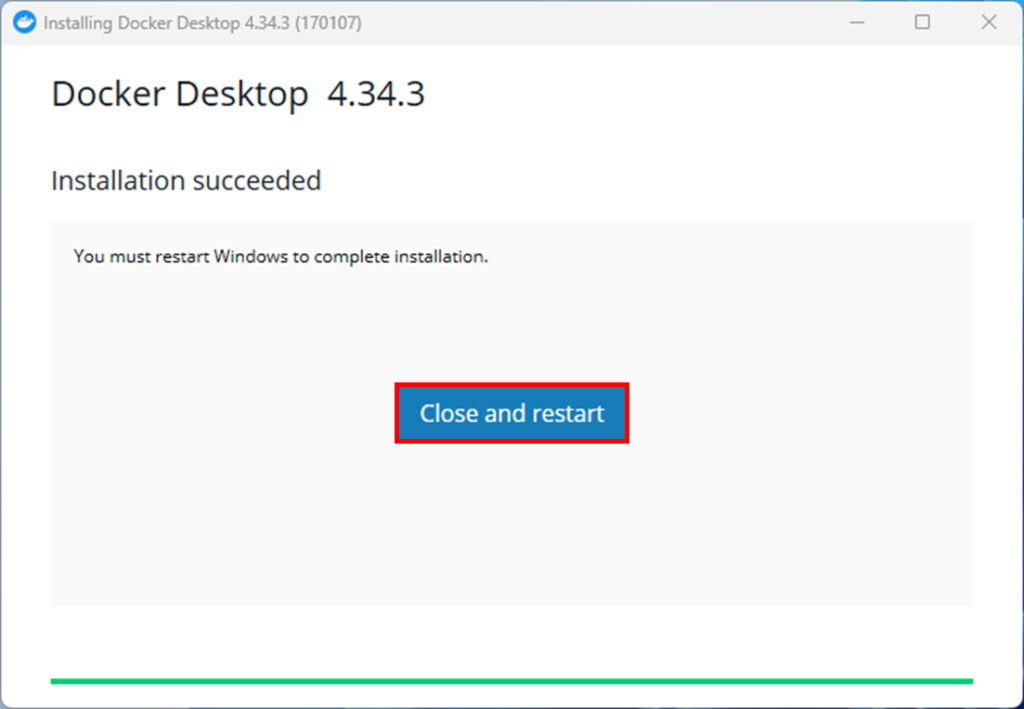
再起動すると、サブスクリプションの同意画面が出ますので、Acceptを押します。
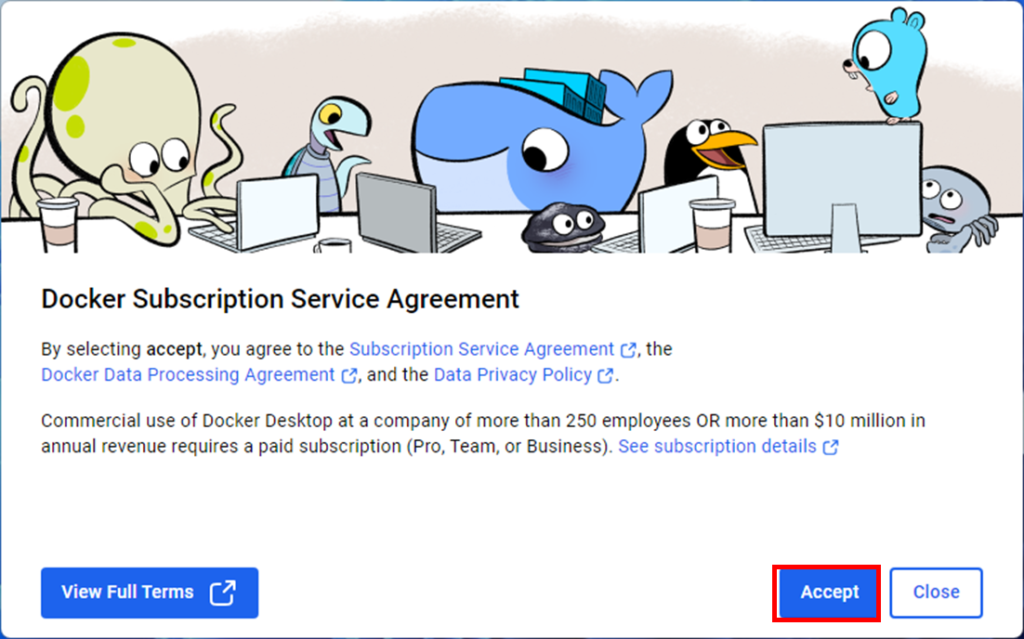
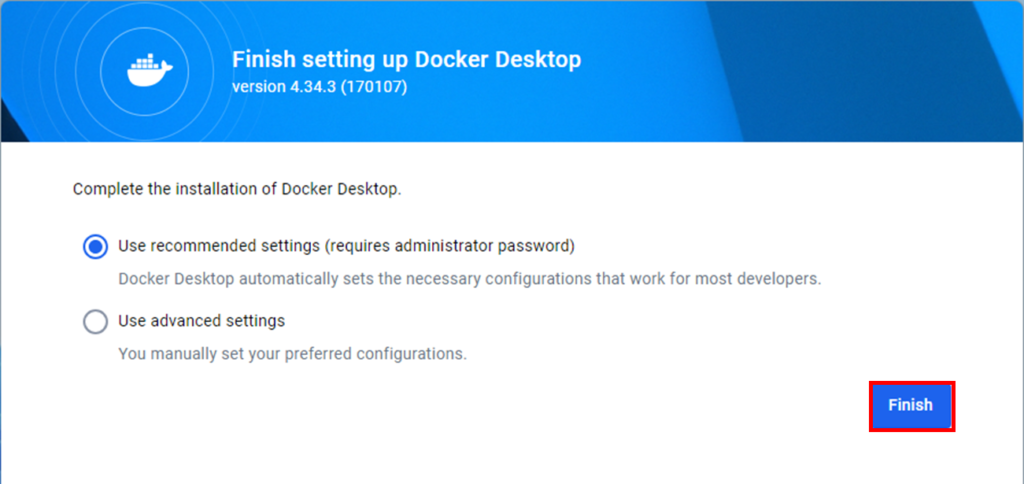
Use recommended settingsを選択して、Finishを押します。
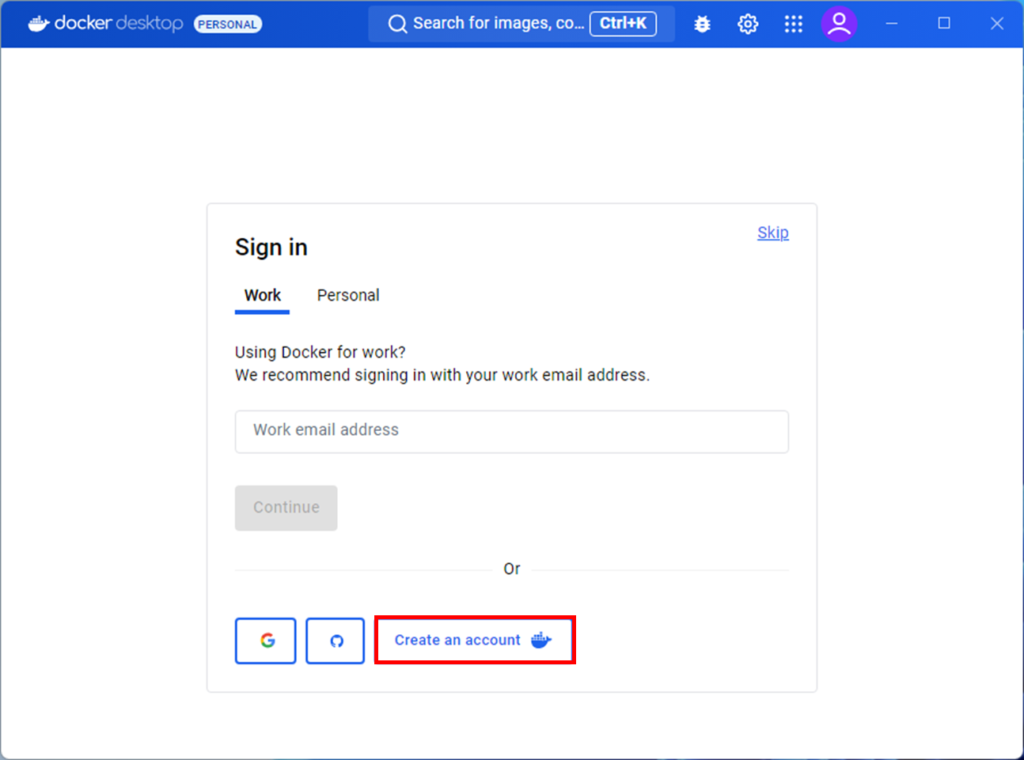
Dockerのアカウントを持ってない場合は、Create an accountでアカウントを作成しましょう。
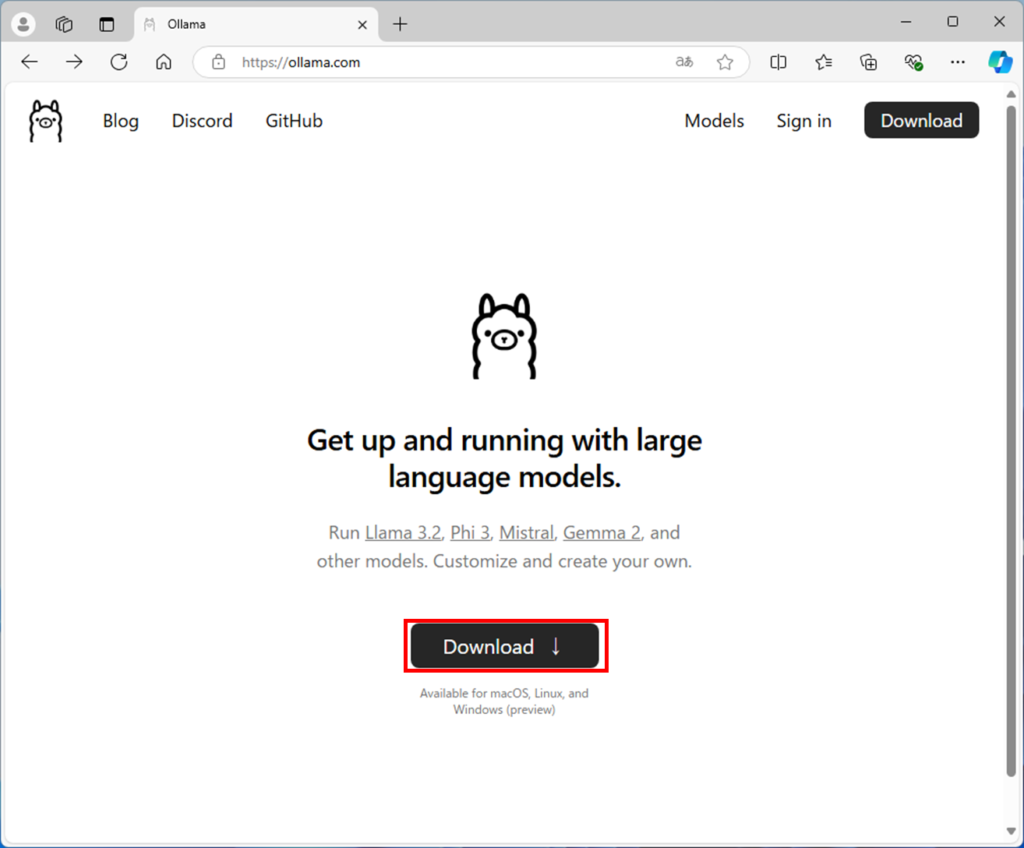
Ollamaのインストール
ollamaをダウンロードします

Downloadを押します。
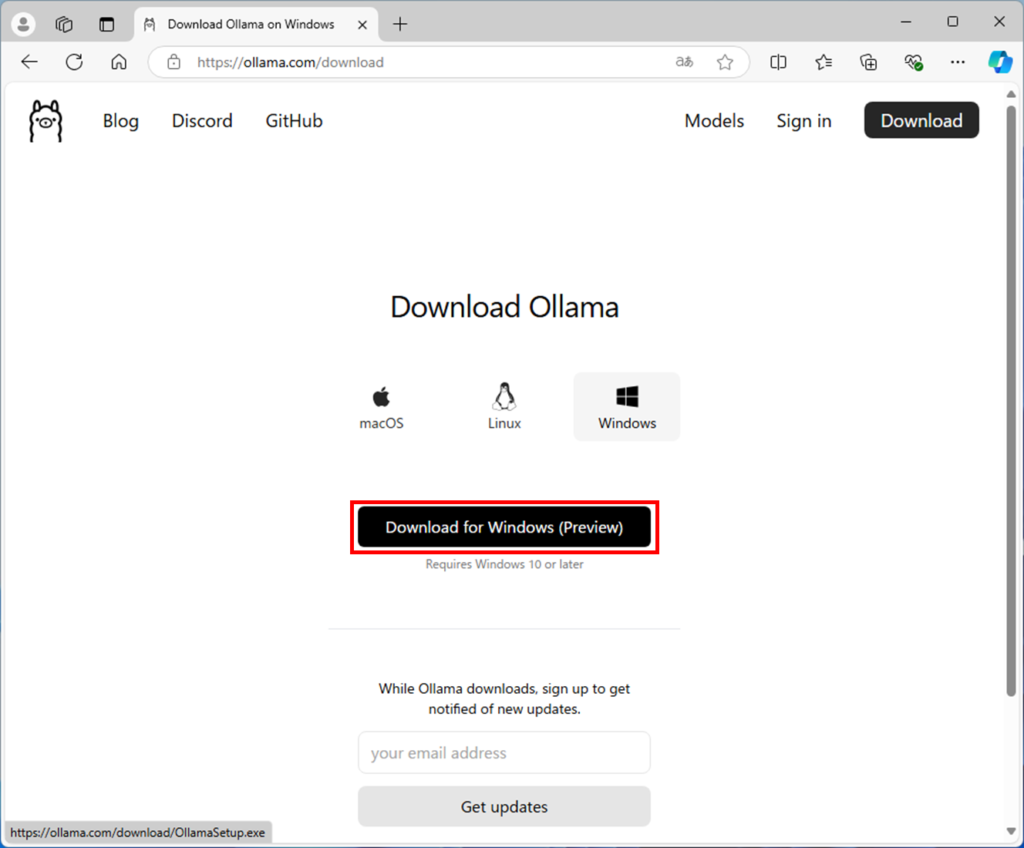
Windowsはプレビュー版のようです。ダウンロードボタンを押します。
OllamaSetupをダブルクリックして、インストーラーを起動します。
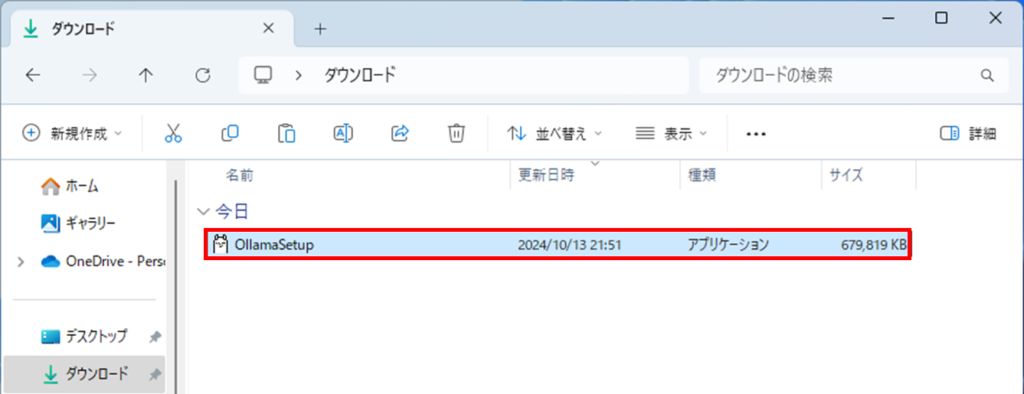
Ollamaのインストール画面が出ますので、Installを押します。
OpenWebUIのインストール
スタートボタンを右クリックして、ターミナル(管理者)を選択します。
下記のコマンドを入力します。
docker loginユーザー名とパスワードを聞いてくるので、Dockerインストール時に作ったアカウントのIDとパスワードを入力します。
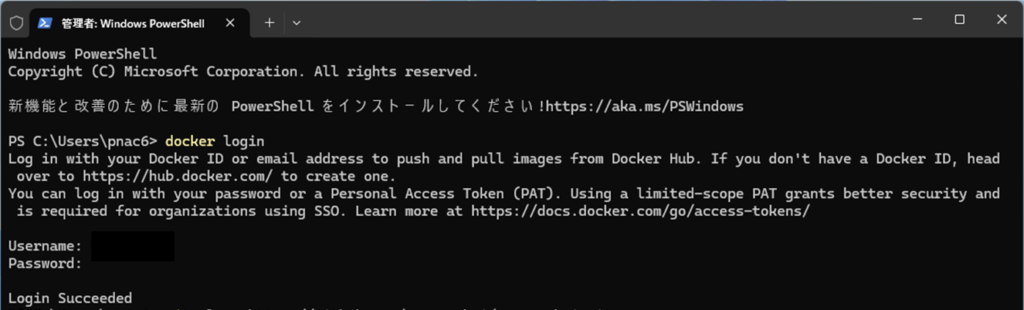
ログインに成功したら、下記のコマンドを入力します。
git clone https://github.com/open-webui/open-webui.gitcd open-webuidocker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainインストールが終わると、DeckerDesktopのコンテナにopen-webuiが追加されます。
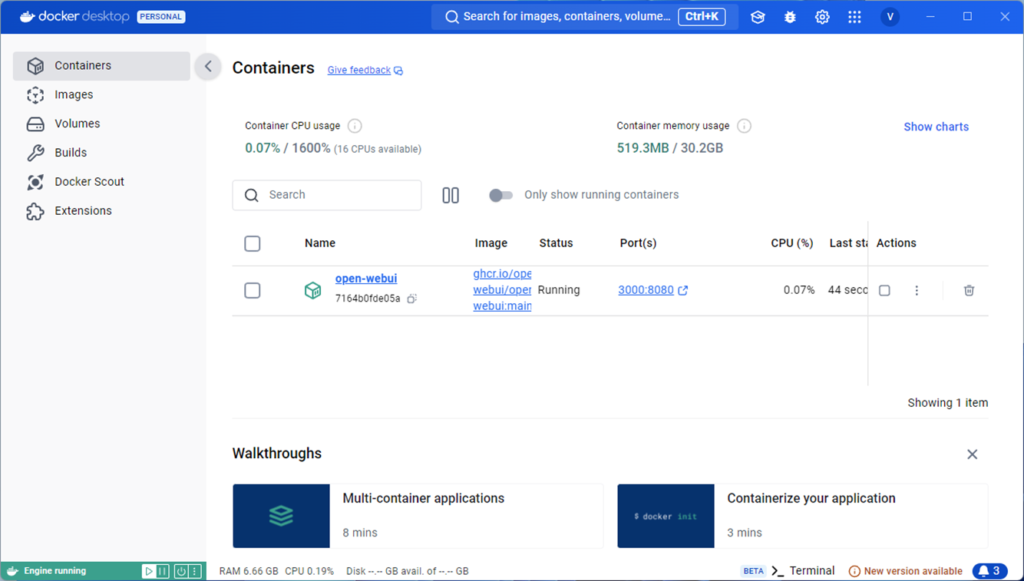
OpenWebUIにアクセスする
インストールしたDockerDesktopとOllamaを起動します。
ブラウザーからhttp://127.0.0.1:3000と入力します。
初回起動時はOpenWebUIのアカウント作成のため、サインアップを押します。
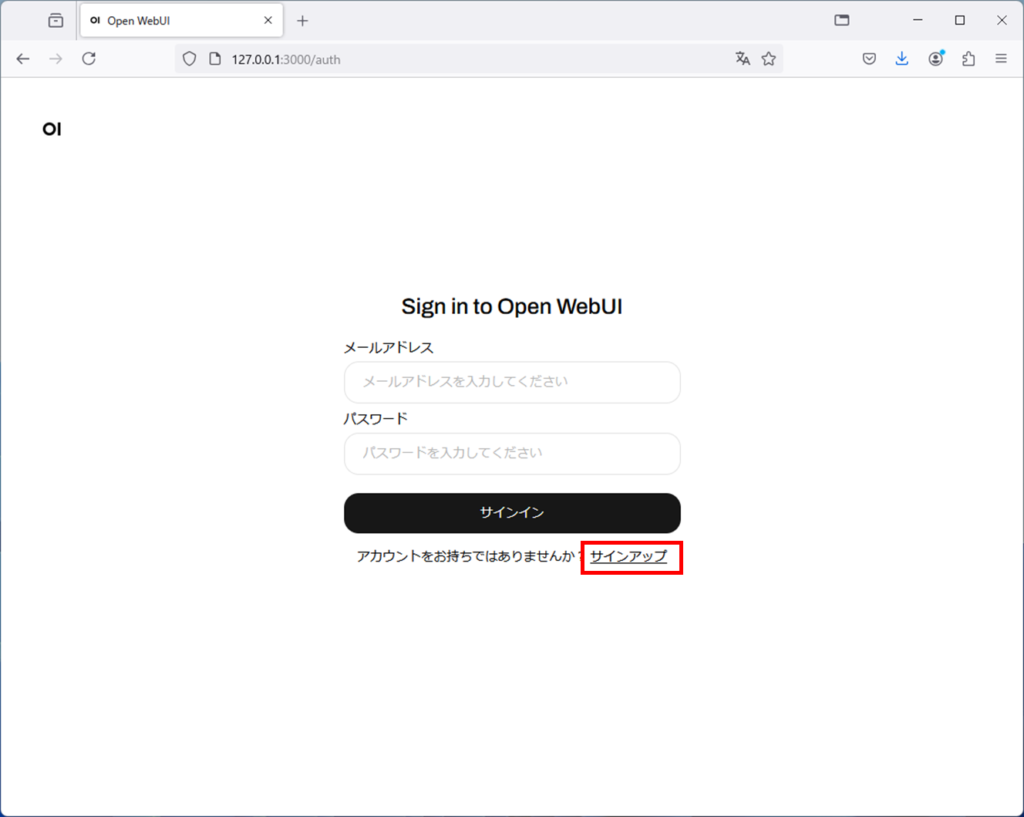
名前、メールアドレス、パスワードを入力して、アカウントを作成ボタンを押します。
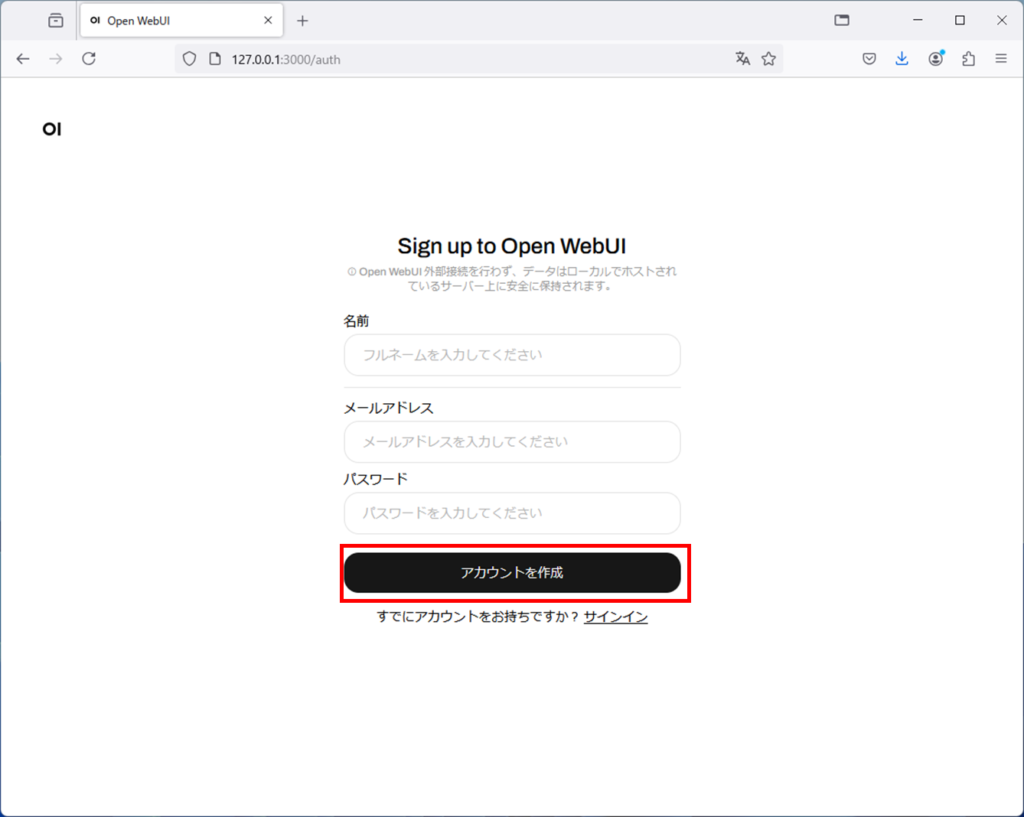
作成したアカウントでログインします。
左上のモデルを選択の部分にモデル名を入力するのですが、
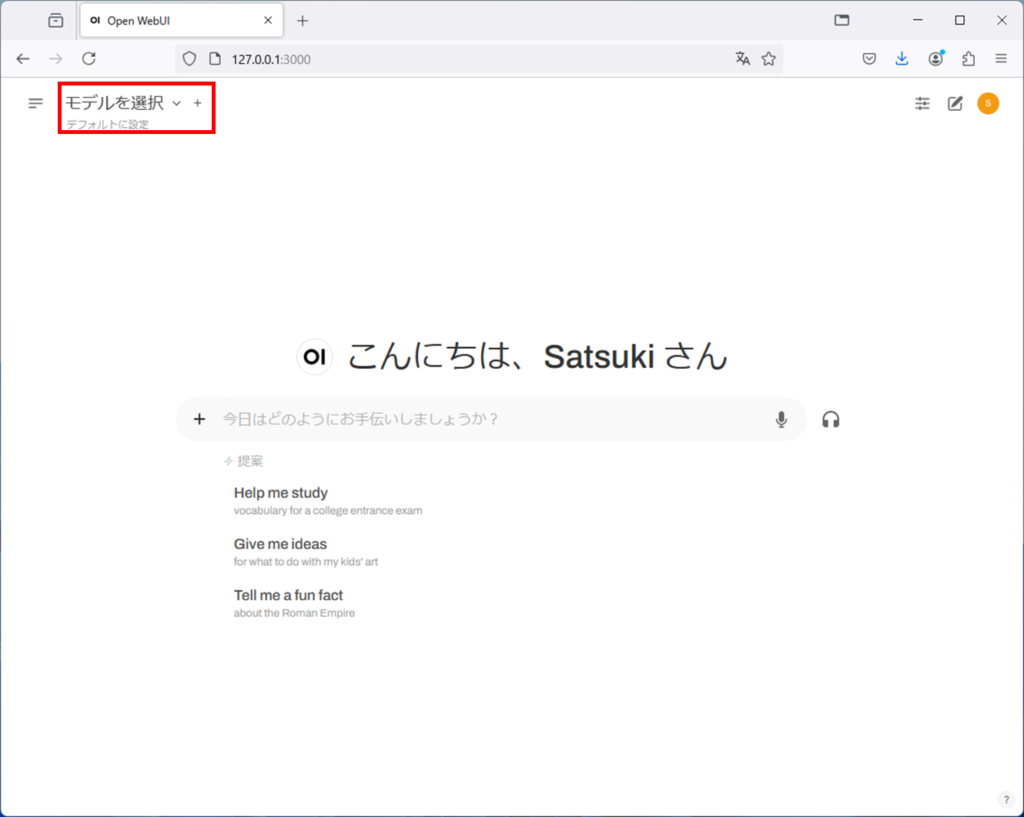
一旦ollamaのサイトに行きます。
Modelsをクリック
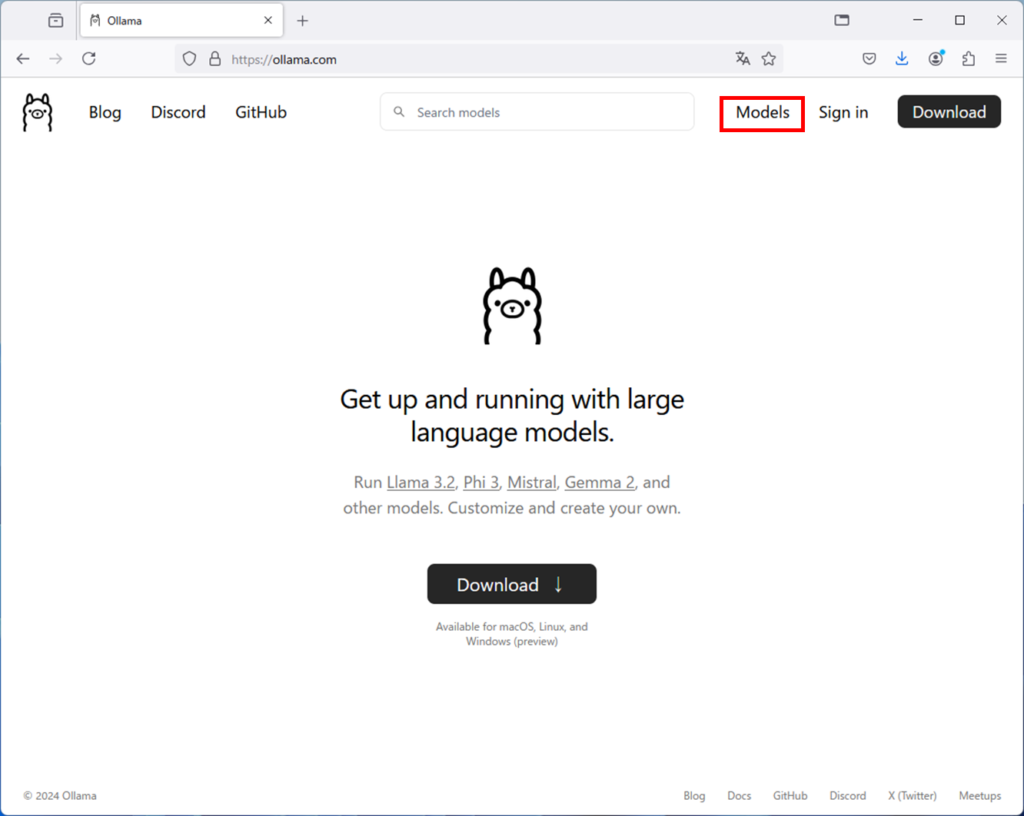
すると、登録されているモデルが表示されます。
ここではgemma2を選択してみましょう。
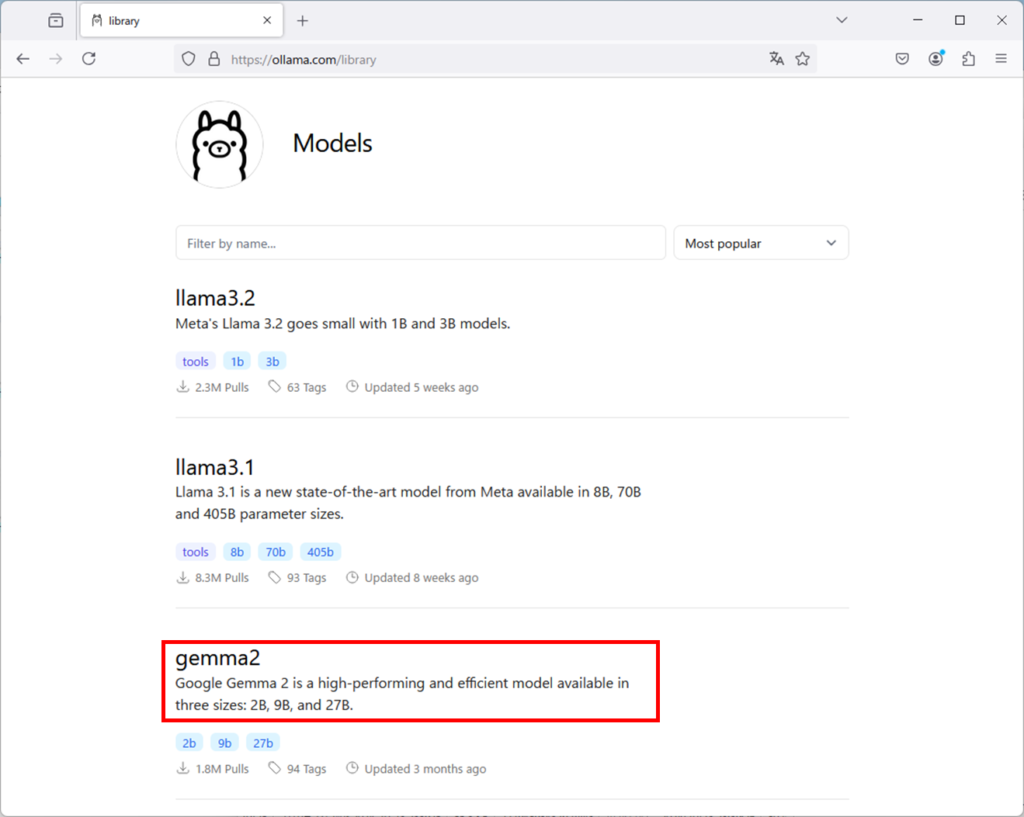
ollama runの右側にあるアルファベットをコピーします。
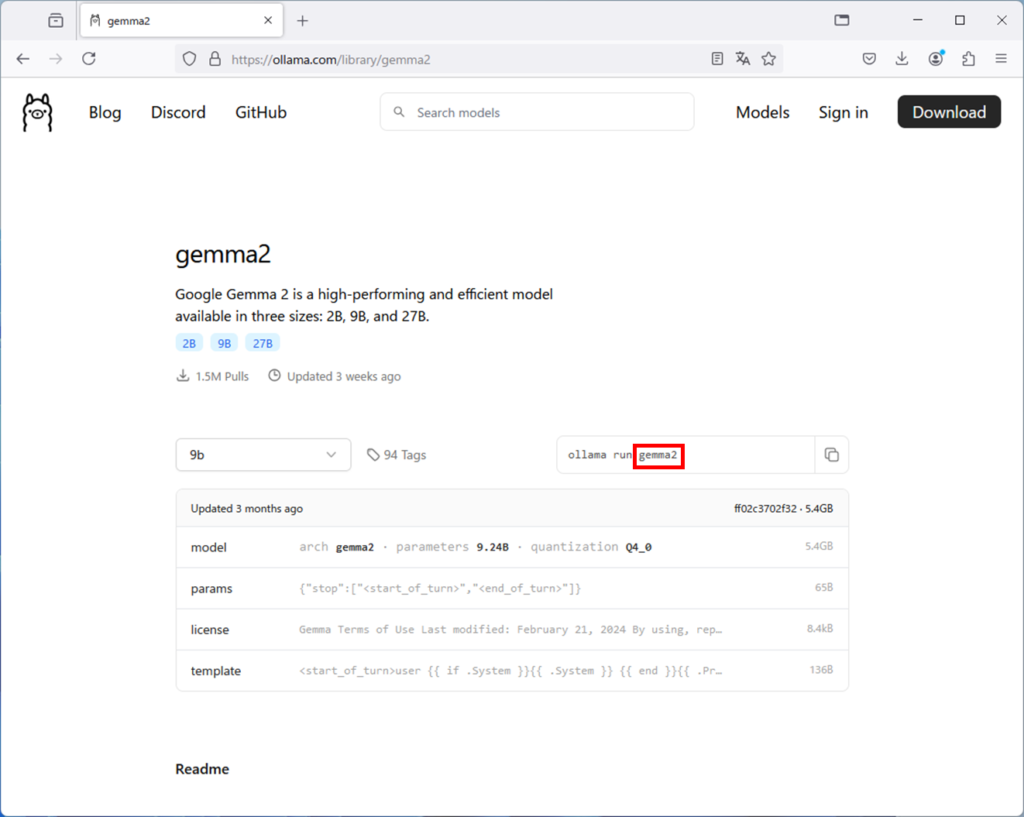
OpenWebUIの画面に戻り、左上のモデルを選択のところにモデル名を入れます。
ここでは、gemma2の文字列を貼り付けます。
その後、Ollama.comから”gemma2″をプルを選択します。
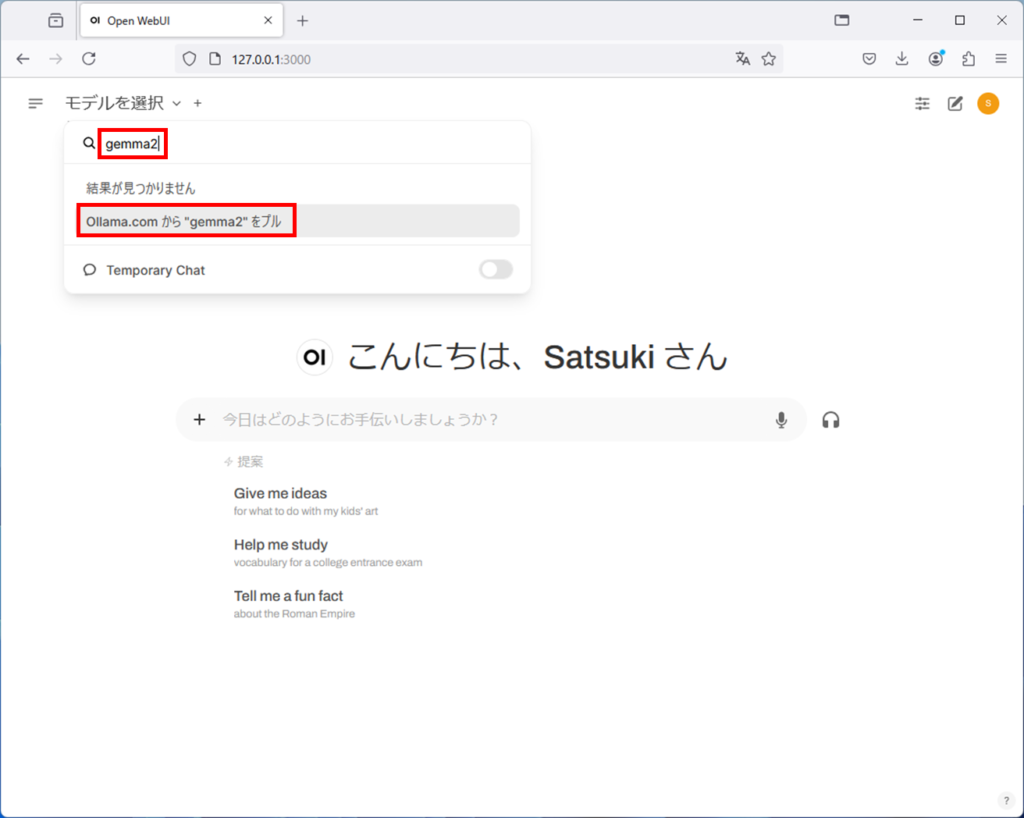
すると、モデルのダウンロードが始まります。
ダウンロードが100%になるまで待ちましょう。
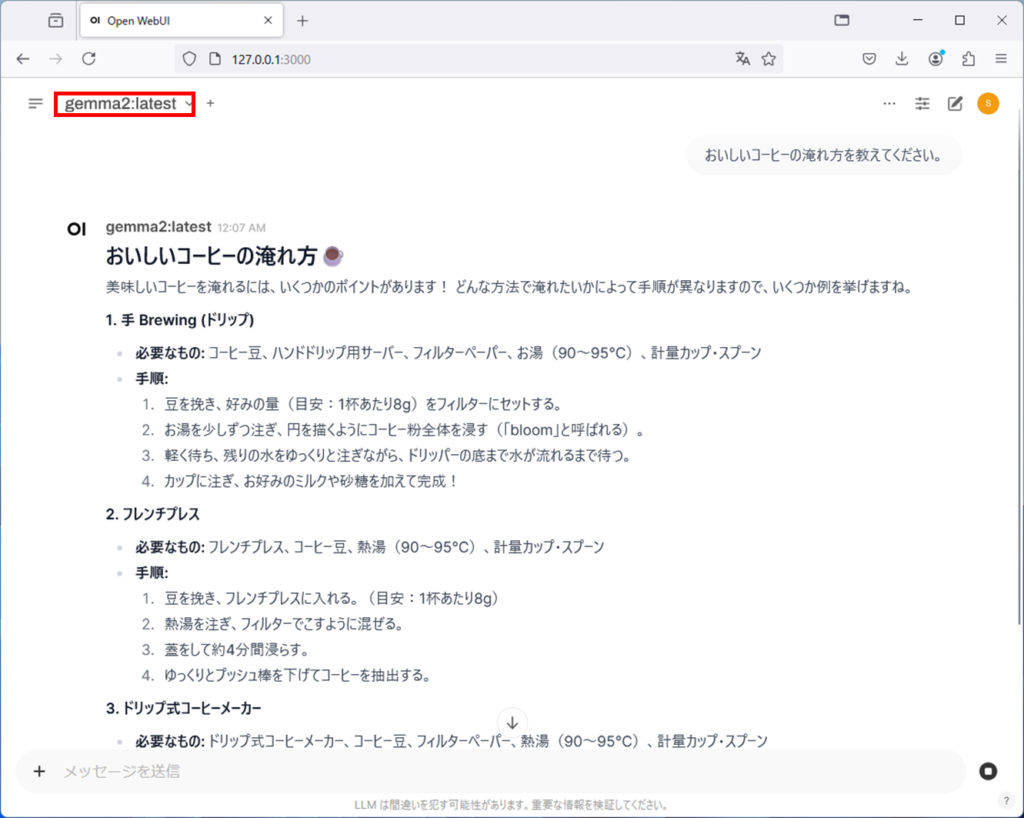
ダウンロードが完了したら、モデルを選択し、gemma2にコーヒーの淹れ方を聞いてみます。
回答が表示されます。
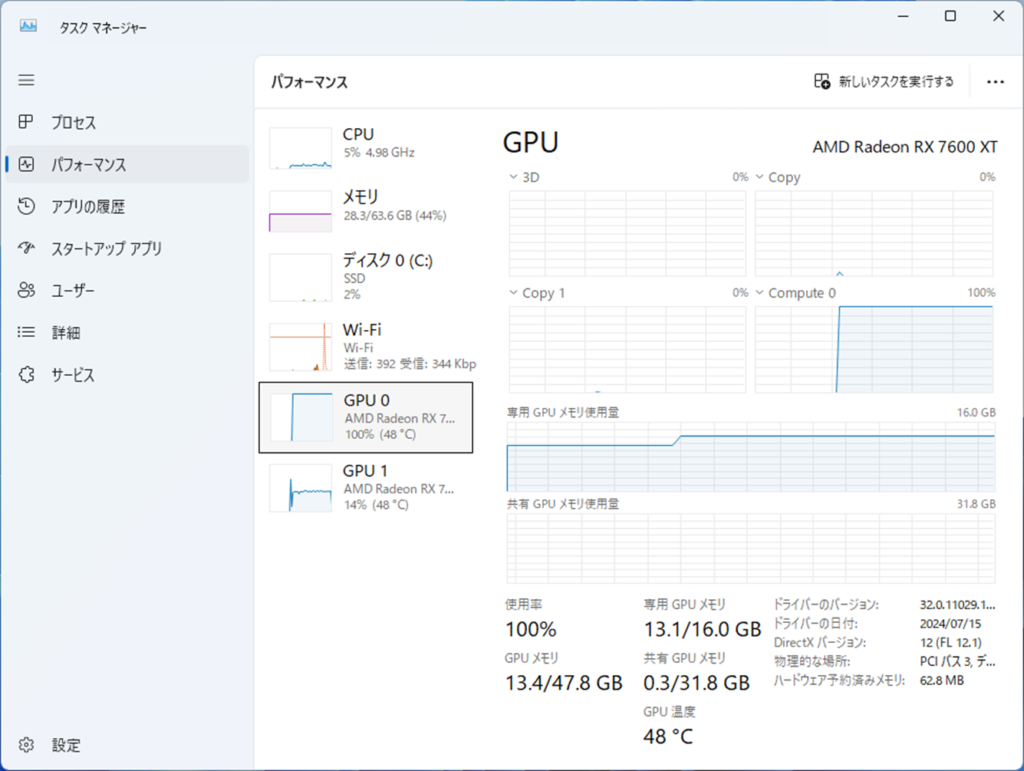
グラフィックボード複数枚挿しについて
OllamaはマルチGPUに対応しているため、グラフィックボード複数枚挿ししている場合、自動で複数のグラフィックボードを使用します。私の環境では、RX7600を2枚使用していますが、実際に動かしてみると、2枚のグラフィックボードを使っていることが分かります。
まとめ
ChatGPTなど、回数に制限があったり、問い合わせた内容が学習に使われるのが嫌な場合は、このようにローカルでLLMを動作させることで問題を解決することができます。色々使ってみましたが、ローカルだから性能が低いということもなさそうでした。今後、ローカルLLMもどんどん進化していくと思われますので、楽しみですね。


コメント